
Kubernetes for ETL
Sep 2020From December 2018 until May of 2020, I worked as a software engineer at Aclima. While I was there, I ended up building an in-house ETL system written entirely in Python on Kubernetes. Though fairly generic, this system is, and likely will remain closed-source. However, I still learned a lot -- about ETL, Kubernetes, data science workflows -- and this post is an attempt to summarize those learnings.
I would love to reflect generally on my time at Aclima, similar to my reflections on leaving Airbnb. I found it difficult to approach this as a single post, so I'm going to do it in pieces, of which this is one. Stay tuned for more posts about other things I learned in the last 18 months.
What's Aclima
When I joined, Aclima had just completed it's Series A, and was focused on building and scaling a new product. The products customers were regulators, such as Bay Area's own BAAQM (or "the district"). These folks are in charge of making the air that citizens in their districts breathe as clean as possible. To do this, they need data -- how good is the air, what are some problem areas or pollutants, what is the effect of various interventions.
Traditionally, that data has primarily come from permanent EPA monitoring sites. These contain very expensive regulatory- or lab-grade equipment that has been strenuously vetted to give accurate readings. This equipment has to be secured and property maintained to retain accuracy. As a result, there are not that many such regulatory sites -- here's a map of the Bay Area ones from the airnow.gov website:
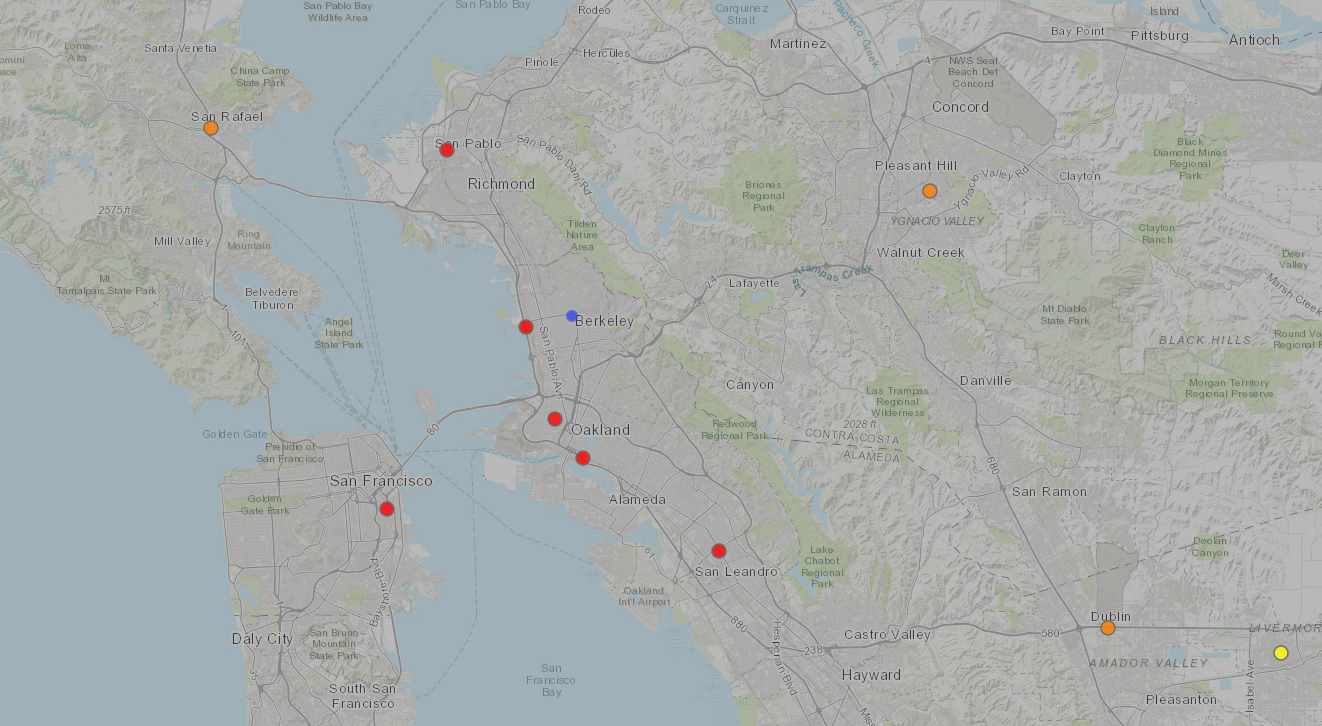
The problem is that, while the reference stations give very accurate data, that data is only very accurate for the small area immediately adjacent to the regulatory site. Air quality, on the other hand, can differ dramatically, even block-by-block. It's strongly affected by the presence of major roadways, toll booths, restaurants, features of the landscape, and many other factors.
Aclima's goal was to quantify this local variability by collecting "hyperlocal" air quality measurements. Even with the advent of low-cost sensors and cheap connected devices, installing and maintaining thousands of devices on every street would be a challenge. Instead, Aclima builds out vehicles equipped with a suite of sensors, and then drives those vehicles down every block -- many times, to collect a representative number of samples.
Overall Architecture
What are the technical details around implementing such a data collection system? There are lots of moving -- sometimes, literally moving -- pieces here. First, a bunch of hardware must be spec'ed, sourced, integrated, and tested. The hardware needs software which can collect data from a suite of sensors, and then the software needs to report this data back to a centralized backend. The data must be collected, stored, and processed. Finally, there's a presentation or product layer, which allows customers to gain insights from the pile of data points.
Over my time at Aclima, I worked on all of these components. For instance, I built a tool which generated STM32 firmware and then flashed it onto boards using dfu-util. I experimented with rapidly prototyping low-cost hardware (post coming soon). I also worked on fleet-level IOT device management and data collection.
However, most of my time at Aclima was spent on the pipeline for processing the data that our vehicles and sensors collected. I'd like to focus this post on the technical details behind this component.
Why Kubernetes?
My immediate project was taking some code written by a data scientist, which had only ever been running on her laptop, and making it run regularly and on some other system. This involved configuring an environment for this code -- the correct versions of python, libraries, and system dependencies. I would need to keep the environment in-sync between the OSX laptops of other engineers and data scientists, and the cloud environment where the code ran in production. I wanted the ability to have representative local tests, but also a rapid-iteration development environment. Finally, I didn't want to introduce too many workflow changes -- only the barest minimum necessary.
The choice of tooling was already somewhat constrained. Aclima was already running in the Google Cloud, and many of their existing services ran in pods on Google's Kubernetes Engine. Most of my experience was with raw EC2 instances configured with chef, and I was unfamiliar with the Docker ecosystem. However, I was also unfamiliar with Cloud ETL tools like Dataflow and was reluctant to jump into a ecosystem new for both myself and my colleagues. The other obvious choice would have been Airflow; Google even has a hosted version. However, at the time (early 2019), Airflow did not have good support for Kubernetes, and I would have had to configure instances for code to execute on.
In any case, my first task was fairly simple -- take a Python program which is already running locally, and make it run in the cloud. I wrote a Dockerfile to correctly configure the environment, copied the code into the docker image, and uploaded it to GCR. I used the Kubernetes CronJob controller to get it to run daily, and K8s secrets to manage credentials for the process. By configuring the cluster autoscaler, we could avoid paying for cluster resources when we didn't need them. Whenever the job ran, if the cluster didn't have enough resources, GKE would automatically add them, and then clean up after the job completed.
The local setup for users involved installing docker and the gcloud tool, and getting gcloud authenticated.
gcloud takes care of managing permissions for the K8s cluster/the kubectl command, which is invoked to deploy the CronJob and Secret manifests.
To shield users (and myself!) from the raw docker and kubectl commands, I immediately added invoke to the data science repo.
After getting the ETL job running locally, the workflow to deploy it to production was a simple inv build and inv deploy.
I also created convenience tooling, like inv jobs.schedule, to do a one-time run of the job in the cloud, and inv jobs.follow to tail it's output.
These initial steps were simple and easy enough that we decided to continue with Kubernetes for a while, and reconsider when we hit snags.
Scaling Up to Multiple Jobs
One job does not an ETL pipeline make. A few changes were required to add a second job to the pipeline. First, we wrote the second job in the same repo as the first. We standardized on a job format -- a Python class with a signature like so:
class PerformType(Protocol):
def __call__(
self, start: pendulum.DateTime, end: pendulum.DateTime, config: Dict[str, Any]
) -> None:
pass
class JobType(Protocol):
perform: PerformType
We then created a standard main.py entrypoint which would accept parameters like the job name and options, and dispatch them to the correct job class.
The Kubernetes work is a little more complicated.
The jobs look basically the same, but have different arguments -- in K8s-speak, the pod spec container args -- are different.
The solution is to template the K8s manifests, but templating a data structure (in this case, yaml) like a string (e.g., with jinja) is a recipe for disaster, and popular tools like jsonnet seem quite heavyweight.
We managed to find json-e, which hit just the right note. This allows you to template and render a pod manifest:
spec:
containers:
- name: {$eval: 'container_name'}
image: {$eval: 'image'}
args: {$eval: 'args'}
with something like:
pod_manifest = jsone.render(
YAML(typ="safe").load('pod_manifest.yaml'),
{
'container_name': job_name,
'image': 'latest',
'args': [job_name, start_time, end_time, job_config]
}
)
You end up with a valid pod manifest as a data structure.
You can then render it into your CronJob manifest:
apiVersion: batch/v1beta1
kind: CronJob
spec:
schedule: {$eval: schedule}
jobTemplate:
spec:
template: {$eval: pod_manifest}
in the same way:
cron_manifest = jsone.render(
YAML(typ="safe").load('cron_manifest.yaml'),
{
'schedule': '0 2 * * *',
'pod_manifest': pod_manifest,
}
)
The resulting cron_manifest can be serialized to YAML again, and passed to kubectl apply to update your resources:
with NamedTemporaryFile() as ntf:
ntf.write(YAML(typ="safe").dump(cron_manifest))
ntf.flush()
os.system(f"kubectl apply -f {ntf.name}")
Of course, we updated our inv tooling to support gathering input from users about which jobs they wanted to deploy, and with which arguments.
We also provided helpers for the main.py dispatcher, so you could specify arguments like yesterday to a job and have it run over the previous day.
Inter-job Dependencies
Soon enough, we had dozens of jobs, and they had inter-job dependencies. You can only go so far by saying "job A runs at 2 am, and usually finishes in an hour, so we'll run job B at 3:30 am".
This was time, again, to re-examine existing popular open-source tooling, and we seriously considered Argo.
But again, some functionality was missing -- specifically, we got bit by this bug preventing the templating of resources, which was a step back from being able to template any part of the manifest using json-e.
Instead, we ended up creating two new concepts.
The first, a workflow, listed all the jobs that depended on each other, along with their dependency relationships, encoding a DAG.
It's easy to parse a YAML list, and verify that it is indeed a DAG, with networkx.
Creating a workflow specification also gave us a place to keep track of standard job parameters, such as command-line options or resource requirements for a job.
(As an aside, resource management for jobs was a constant chore, especially as the product was scaled up and data volumes increased.)
The second concept was a dispatcher job.
Instead of actually doing ETL work, this type of job, when dispatched using a CronJob resource, would accept a workflow as an argument, and then dispatch all the jobs in that workflow definition.
A job would not get dispatched until the jobs it depended on completed successfully.
This allowed us to schedule a workflow to run daily instead of scheduling a pile of jobs individually.
Most of the code was re-cycled from the code already used by users locally to schedule their jobs -- the dispatcher was doing the same thing, just from inside Kubernetes.
Monitoring via Web UI
As the complexity of the ETL pipeline grew, we began encountering workflow failures. We needed an audit log of which jobs ran for which days, so we could confirm that we were delivering the data we processed. We also needed tooling to reliably re-process certain days of data, and keep track of those re-processing runs.
By this point, the ETL system we were building had run for a year without requiring any UI beyond the one provided by GKE and kubectl.
However, to manage the complexity, it seemed like a UI was needed.
I ended up building one using firestore, React, and ag-grid.
Previously, the dispatcher job that ran workflows was end-to-end responsible for all the jobs in the workflow.
It ran for as long as any job in the workflow was running.
If any of the jobs failed the dispatcher would exit, and the subsequent jobs would not run.
Likewise, if dispatcher itself failed, remaining workflow jobs would be left orphaned.
Instead, we turned the workflow dispatcher into something that merely manipulated the state in firestore.
The job would parse the workflow .yaml file into a DAG, and then create firestore entries for each job in the graph.
The firestore entry would include job parameters like command-line arguments and resource requests, as well as job dependency information.
Jobs at the head of the DAG would be placed into a SCHEDULED state, while jobs that were dependent on other jobs were placed into a BLOCKED state.
An always-running K8s service called scheduler would subscribe to firestore updates and take action when jobs were created or changed state.
For instance, if a job was in the SCHEDULED status, the scheduler would create pods for those jobs via the K8s API, and then mark them as RUNNING.
If a task finished (by marking itself as COMPLETED), the scheduler would notice, and clean up the completed pods.
It would also check if any jobs were BLOCKED waiting on the completed job, make sure all their dependencies had completed, and placed them into the SCHEDULED state.
If a job marked itself as FAILED (via a catch-all exception handler), we had the option to track retries and re-schedule the job.
Because the scheduler became the only thing that interacted with the K8s API, it made building user-facing tooling easier.
Those tools merely had to manipulate the DB state in firestore.
This enabled less technical users, without gcloud or kubectl permissions, to create, terminate, restart, and monitor job and workflow progress.
From what I can tell, components like the scheduler are often built using K8s operators and custom resources.
However, we found that just running a service with permissions to manage pods is sufficient.
This avoids having to dive too deep into K8s internals, beyond the basic API calls necessary to create and remove pods and check on their status.
Parallelism
Some jobs in our system were trivially parallelise-able, e.g. because they processed a single sensor's data in isolation.
The system of using the scheduler to run additional jobs unlocked infinite parallelism inside jobs.
For instance, we could schedule a job like ProcessAllSensors.
This job would first list all sensors active during the start/end interval, and then could create a child job in firestore for each sensor.
Creating child jobs was as simple as writing a job entry into firestore, with the ID of the sensor to process.
Parallelism was limited only by the auto-scaling constraints on the K8s cluster.
I created an abstraction called TaskPoolExecutor, based on the existing ThreadPoolExecutor.
Each job submitted to the executor would run in a different K8s pod.
Not only did this make data processing much faster, but more resilient, too.
Previously, if a particular sensor failed in it's processing, restarting that processing was complicated.
In the new system, the existing retry system baked into the scheduler could retry individual sensors, without the parent job even knowing about it.
Takeaway
My focus at Aclima was on business objectives -- making sure data is delivered, data scientists and other technicians are productive, and we can manage our fleets of vehicles and devices. In 18 months, I was able to build an infinitely-auto-scalable, reliable parallel job scheduling system and UI accessible to non-technical users. I was able to build this one step at a time, from "how do I regularly run one cron job" all the way to "how to I parallelize and monitor a run of a job graph over a year of high-precision sensor data".
I think this is a tribute to the power of the abstractions that Kubernetes provides. It's an infinite pile of compute, and it's pretty easy to utilize it. This experience has sold me on the premise, and I would definitely use Kubernetes for other projects again.
Do Differentlys
The scheduler and all the code that interacts with K8s was written in Python, mostly because the data processing code was also written in Python.
However, as soon as I wanted to add a UI, I had to begin writing Javascript.
This means I have to share at least data structures -- for instance, the structure of a job in firestore -- between the two languages.
In the future, if I'm writing a UI, even a CLI, I will consider strongly whether I should just write it in JS to begin with.