\n\n
\n\n## Rigging The Mainsail\n\nA friend had a giant cache of [twinkly strings](https://twinkly.com/en-us/products/strings-multicolor).\nOur plan was to hang them up in the mainsail triangle, and display some cool mapped patterns in 2D.\nHere's our rigging plan:\n\n\n\nI was really worried about losing the main halyard, so we used a serious line with some extra-redundant knots to secure it at the mainsail clip and on the deck.\nFor the rigging, we used paracord with some alpine butterflies tied into it:\n\n\n\nThe first few twinkly strings, next to the mast, used the entire length of the string.\nFor the later strings, we could start at the top, go back down to the boom, then go back up to the top again.\nThis required hosting the rigging, figuring out where the string would end up, and securing it on the rigging that ran along the boom.\nThen we could lower the whole rigging, and secure the other end of the string in the loop that ran along the topping lift.\n\nThis was a huge pain.\nChristmas lights **want** to get tangled, and hosting them up and down gives them just the chance they're looking for.\nIt took us until the very end to figure out that we could just put extra paracord through the loops, and use it to hoist one string at a time.\nNext time, we'll definitely just install extra paracord in every loop from the very beginning.\n\nWe ended up using 2 strings of 400 lights, and 1 string of 600 lights -- 1400 LEDs total on just the mainsail triangle.\n\n## Mapping\n\nWe hoped to use the Twinkly app to map the lights to a 2D image.\nThis **absolutely** did not work.\nFirst, the mast is really tall -- it was difficult to even get the whole set of lights in the frame.\nTo do that, we had to stand pretty far back, which made each LED hard to distinguish in the picture.\nFinally, the strings swayed in the wind, and the whole boat rocked in the water -- no way to get a still image.\n\nThankfully, with just the default unmapped patterns, the Twinkly lights look pretty good.\nHowever, I am now kind of obsessed with the idea of mapping the lights to a 2D image.\nI think using a hybrid automatic-manual approach should work well.\nI should be able to take a single photo as the base of the scene.\nThen, I should be able to turn on sections of the lights, and then indicate their position in the base image.\nIt doesn't have to be perfect -- just good enough to get the general shape of the boat.\n\nI would like to try writing some software for this in time for next year's parade.\n\n## Other Lights\n\nI bought some of [these lights](https://amzn.to/3RSKvv1) to put on the lifelines.\nMy plan was to control them with [WLED](https://kno.wled.ge/).\nBut I discovered that, though they are individually addressable, they have some bug in the implementation of the protocol that causes them to flicker unpredictably.\n\nI did bring some of [these strings](https://amzn.to/3NI0LfP).\nUnlike the previous lights, these don't explicitly advertise WS2812.\nHowever, they do work well with WLED.\nTheir implementation of WS2812 is kind of [odd](https://todbot.com/blog/2021/01/01/ws2812-compatible-fairy-light-leds-that-know-their-address/).\nRather than shifting out the bits for the next light, they allow the controller to wiggle the entire common data line, and each LED knows its own address.\nThis means you cannot link multiple strands together serially -- the second string will just mirror the first.\n\nI didn't have time to do anything fancy with these lights.\nWe used them with their default controllers using some built-in patterns.\n\n## Future Work\n\nFor next time, I would dispense with the fancy Twinkly lights (which, wow, are pretty expensive!).\nInstead, I would use the cheap strings off Amazon and write my own software to control them over WS2812.\nLet me know if you have ideas for how to create a 2D mapping UI for this!\n\n## The Parade\n\nOh yeah, there was a parade!\nThat part was super-fun.\nWe got to see all the other boats up-close, and listening to the marine radio chatter with the stressed-out parade organizers trying to keep everything going was pretty entertaining.\nNext time I would like some other crew to feel confident driving -- turns out operating a 40' boat in close quarters with a bunch of other boats, in the dark, in a shallow marina, is stressful!\nWe didn't win any prizes, but we had a great time.\n", "url": "https://igor.moomers.org/posts/light-up-boats", "title": "Light Up Boat Parade 2023", "summary": "We decorated a boat for the Sausalito light-up boat parade!\n", "image": "https://igor.moomers.org/images/lights.png", "date_modified": "2023-12-18T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/secrets-in-docker-compose", "content_html": "\nTL;Dr: store your secrets in `git` alongside your `compose.yml` file.\nMy new service, [`dcsm`](https://github.com/igor47/dcsm), decrypts the secrets and templates them into your config files.\n\n## Primer on `docker compose` Repos\n\nLately, there's been a thriving ecosystem for running self-hosted services using `docker`.\nPackaging services with docker means abstracting away the complexities of configuring a local environment.\nUpdates are consistent across services.\nPlus, there are lots of utilities to make life easier.\nFor instance, [`traefik`](https://traefik.io/) will automatically terminate SSL and reverse-proxy to your service -- no more manual certificate management.\nAs a result, I am running increasingly more services using `docker compose` files.\n\nI consider each `compose.yml` file to define a \"cluster\" of services that are logically grouped.\nFor instance, I have a media cluster that handles movie ([jellyfin](https://jellyfin.org/)), music ([navidrome](https://www.navidrome.org/)), book ([calibre-web](https://github.com/janeczku/calibre-web)), and audiobook ([audiobookshelf](https://www.audiobookshelf.org/)) hosting services.\n\nI keep each cluster in its own git repo.\nThe repo includes the `compose.yml` file and the configuration for all the services in that file.\nMany services do not need any configuration beyond what is in the [`environment` key](https://docs.docker.com/compose/compose-file/compose-file-v3/#environment) of the `compose.yml`.\nOften, though, a config file is required or is a more ergonomic way to specify the configuration.\nFor instance, all my clusters have a `config/traefik/traefik.yml` file to configure `traefik`.\nI then bind-mount the config files into the container filesystem:\n\n```yaml\nvolumes:\n - ./config/traefik:/etc/traefik\n```\n\n## How to Manage Secrets?\n\nSuppose I need a credential inside that config file?\nBefore writing [`dcsm`](https://github.com/igor47/dcsm), I was at the mercy of the service author.\nFor instance, every piece of `grafana`'s configuration [can be overridden with environment variables](https://grafana.com/docs/grafana/latest/setup-grafana/configure-grafana/#override-configuration-with-environment-variables).\nSo, I could check a `grafana.ini` file into the repo with most of my config.\nThen, to add a secret (e.g., an OpenID-Connect client id/secret pair), I would:\n\n1. create a `grafana/environment` file containing just the overridden secret keys\n1. add the file to `compose.yml` under `env_file`:\n\n```yaml\ngrafana:\n env_file:\n - path/to/grafana/environment\n```\n\nThis is confusing -- now the configuration is split between several places.\nAlso, the `grafana/environment` file could not be checked into the repo.\nIts management becomes out-of-band; as a DevOps practitioner, I don't like that.\n\nGrafana is one of the better services here.\nLots of services require using a config file.\nSometimes, you can extract just the secret-containing part of the config and manage *that* out-of-band.\nThen there are services like [`synapse`](https://matrix-org.github.io/synapse/latest/usage/configuration/config_documentation.html) which requires a bunch of secrets in a common config file and has no mechanism for either including environment variables in the config or sourcing sub-files.\nNow, your entire config file cannot be checked into the repo.\n\n## DCSM\n\n[`dcsm`](https://github.com/igor47/dcsm) is a simple service containing some python code and [`age`](https://age-encryption.org/) for symmetric-key encryption.\nTo use DCSM, you add it to your `compose.yml`:\n\n```yaml\n dcsm:\n build: .\n environment:\n - DCSM_KEYFILE=/example/key.private\n - DCSM_SECRETS_FILE=/example/secrets.encrypted\n - DCSM_SOURCE_FILE=/example/secrets.yaml\n - DCSM_TEMPLATE_DIR=/example/templates\n volumes:\n - ./example:/example\n```\n\nThe variables `DCSM_KEYFILE` and `DCSM_SECRETS_FILE` are required for basic operation.\nYou may optionally set `DCSM_SOURCE_FILE` to tell `dcsm` about your unencrypted secrets source.\nThis allows you to use the `encrypt` and `decrypt` commands, though you can also perform those operations by running `age` locally.\n\nYour secrets source is a `yaml` file containing your secrets.\nFor example:\n\n```yaml\nGRAFANA_OAUTH_CLIENT_ID: this_is_secret\nGRAFANA_OAUTH_CLIENT_SECRET: \"this is also a secret\"\n```\n\nThis file, along with your `DCSM_KEYFILE`, should be `.git-ignore`ed from your repo\nThe keyfile must be copied out-of-band between your dev environment and your cluster runtime machine.\n\nYou may set any number of directories with the environment variable prefix `DCSM_TEMPLATE_`.\nIn these directories, `dcsm` will find files ending with `.template` and replace template strings with secrets from your encrypted `DCSM_SECRETS_FILE`.\nFor example, here is that grafana config file:\n\n```ini\n[auth.generic_oauth]\nenabled = true\nclient_id = $DCSM{GRAFANA_OAUTH_CLIENT_ID}\nclient_secret = $DCSM{GRAFANA_OAUTH_CLIENT_SECRET}\nscopes = openid profile email\n```\n\nThis approach enables you to keep your cluster repo consistent.\nYou can easily refer to a secret in multiple places.\nFinally -- if you need to pass secrets as environment variables, you can just template an `env_file`.\nFor instance, your template could be:\n\n```bash\nGF_AUTH_GENERIC_OAUTH_CLIENT_ID=$DCSM{GRAFANA_OAUTH_CLIENT_ID}\nGF_AUTH_GENERIC_OAUTH_CLIENT_SECRET=$DCSM{GRAFANA_OAUTH_CLIENT_SECRET}\n```\n\nIf you store this file in your repo at `config/grafana/oauth.env.template`, then you could use it like so:\n\n```yaml\nservices:\n dcsm:\n image: ghcr.io/igor47/dcsm:v0.3.0\n environment:\n - DCSM_KEYFILE=/secrets/key.private\n - DCSM_SECRETS_FILE=/secrets/secrets.encrypted\n - DCSM_SOURCE_FILE=/secrets/secrets.yaml\n - DCSM_TEMPLATE_DIR=/config\n volumes:\n - ./secrets:/secrets\n - ./config:/config\n\n grafana:\n image: grafana/grafana-enterprise\n restart: unless-stopped\n depends_on:\n dcsm:\n condition: service_completed_successfully\n env_file:\n - ./config/grafana/oauth.env\n```\n\nYou can see that `grafana` has a `depends_on` the success of `dcsm`.\nThis allows `dcsm` to run first and template your config files with your secrets.\nBy the time the `grafana` service starts, the config files are ready for action!\n\n## That's It\n\nI wrote this tool to meet my own need, but I hope others will find it useful as well.\nI think managing clusters via a configuration-as-code/infrastructure-as-code repo works pretty well.\nSecret management was the missing piece -- but, with [`dcsm`](https://github.com/igor47/dcsm), no longer.\n", "url": "https://igor.moomers.org/posts/secrets-in-docker-compose", "title": "Docker Compose Secrets Manager", "summary": "A service and an approach for managing secrets in docker compose repos.\n", "image": "https://igor.moomers.org/images/whales-with-secrets.png", "date_modified": "2023-12-15T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/soviet-kgb-stories-pt2", "content_html": "\n**Note**: There is a [previous post](/posts/soviet-kgb-stories-pt1), about my uncle.\n\nI never met my grandfather Lev -- he died (of stubbornness) just about a year before I was born.\nBut I heard lots of stories.\nIn the land of [блат (blat)](https://en.wikipedia.org/wiki/Blat_(favors)), the person in charge of the pharmacy containing scarce but potentially life-saving medication is a good person to have on your side.\nAnd my grandfather, by all accounts, knew how to play the game.\nIn my home city of Nikolaev, everyone knew him, and everyone owed him a favor -- therefore, or possibly also, everyone respected him.\n\nMy grandfather could possibly have aspired to a greater status than a two-bedroom apartment in a [хрущёвка](https://en.wikipedia.org/wiki/Khrushchevka) and the once-yearly government-sponsored vacation to the Black Sea.\nIn his later years, he was offered an opportunity to join [The Party](https://en.wikipedia.org/wiki/Communist_Party_of_the_Soviet_Union) -- a key opportunity for advancement in the USSR.\nBut he turned it down, and this is the story of why.\n\n## Some Flavor\n\nBefore we get into the meat of my story, an anecdote.\n\nThere's a common expression among Soviet Jews, which goes \"Бьют не по паспорту, а по морде.\"\nTransliterated -- \"biut-ne-po-pasportu-a-po-morde\".\nTranslated -- \"they punch you, not in the passport, but in the face\".\n\nThis is a reference to the [\"Пятая графа\"](https://ru.wikipedia.org/wiki/%D0%9F%D1%8F%D1%82%D0%B0%D1%8F_%D0%B3%D1%80%D0%B0%D1%84%D0%B0) -- the \"fifth line\" of the Soviet passport, which described the passport-holder's \"Nationality\".\nFor Soviet Jews, this line was filled in, \"Jewish\", and it served to close many doors.\nBut -- they don't punch you in the passport.\nAnti-semites are keenly attuned to stereotypical ethnic features, and it was enough to simply look Jewish to get into trouble.\n\nLev, for what it was worth, didn't look particularly Jewish.\nSo, when he showed up at my grandmother's house to ask her father for her hand, he was at first confused for a government inspector coming for a surprise visit to their family pharmacy.\nWhile they figured out what to do with him -- the chaos abated somewhat when my grandmother's precocious kid brother announced, \"That's not an inspector, that's Sofia's boyfriend!\" -- they bustled him into the kitchen.\n\nMy grandmother's grandmother was tasked with feeding Lev, which she went about grudgingly.\nBecause he didn't look Jewish, she felt free to mutter her complaints in Yiddish while she served him food.\n\"They put this goy in my kitchen, and I have to feed him?\nWhat's next, he's gonna ask for an (alcoholic) drink?\"\n\nMy grandfather, however, spoke fluent Yiddish.\nHe learned it at a yeshiva in Kherson, which he attended at the same time as my grandfather Semyon -- they actually knew each other in school, decades before my dad met my mom in Nikolaev.\nSo, hearing the muttering, he responded, \"Actually, a shot of vodka wouldn't go amiss.\"\nWhen the old woman realized that the suitor was actually Jewish after all, her reluctance instantly disappeared.\nMoments later the table was covered with the best in the house.\n\n## The War Years\n\nOn June 22nd, 1941, Germany declared war on the Soviet Union.\nMy grandfather Lev had just finished his first year of medical school, and he was immediately drafted.\nHe ended up serving as a medic on the front lines through the entire war.\nAfter Germany surrendered in 1945, Lev was not immediately released from the military.\nHe ended up serving in the occupation for another year, helping rebuild medical facilities in a Germany that had been reduced to rubble by the Allied campaign.\n\nWhen Lev finally returned to Odessa in October of 1946, his medical school had already finished more than a month of classes.\nHe was told to come back the following year to restart his education.\nLev was already way behind -- he would be four or five years older than his classmates -- and he didn't want to put life off for another year.\nWandering around Odessa, he saw an announcement that the pharmacy school was still recruiting students.\nMy grandmother had actually seen the same announcement when she showed up in Odessa to start school, a little late due to illness.\nAnd that's why I'm here to write this story today!\n\n## After School\n\nMy grandparents were married in 1949, and my uncle from [the previous story](/posts/soviet-kgb-stories-pt1) was born in 1950.\nThey moved to Nikolaev, where my grandfather immediately became the head of the pharmacological supply warehouse.\nI tried to figure out why a kid right out of school was immediately in charge of a medical warehouse.\nIt seems to boil down to two reasons.\nThe first is a massive shortage of men in the aftermath of the war.\nWhile Soviet casualties [are disputed](https://en.wikipedia.org/wiki/World_War_II_casualties_of_the_Soviet_Union), they total at least 9 million soldiers, all men.\nThe disputes all purport the official figures to be much too low, and there are estimates as high as 40 million military and civilian deaths -- twice as much as official figures.\n\nThe second reason is that the USSR had what, by modern US standards, unreasonably generous medical leave.\nThere was a baby boom in the USSR, just as there was in the US, and women were going into декрет, making them unreliable employees.\n\n## Arrest, Exile, and Release\n\nAs Lev was running the pharmaceutical warehouse, the USSR was in the grips of a paranoid Stalin.\nAs a result of the [Doctors' plot](https://en.wikipedia.org/wiki/Doctors%27_plot), many Jewish doctors and medical workers were \"dismissed from their jobs, arrested, and tortured to produce admissions\".\n\nIn 1951, Lev was using petty cash from his warehouse to purchase newspapers, which he hung up on the walls for public reading.\nBecause of this, he was accused by the local KGB of \"misappropriation of public funds\".\nIn a swift trial, he was pronounced guilty.\n\nAt this time, the USSR was in a Nuclear arms race with the USA.\nUranium ore was discovered in [Жёлтые Воды (Yellow Waters)](https://en.wikipedia.org/wiki/Zhovti_Vody), and the USSR needed people to mine the ore.\nI cannot tell if the Yellow River was actually yellow because of yellowcake uranium, or if the color was a coincidence.\nIn any case, Lev was sent to this region of Ukraine to work in the mines.\n\nBecause of his medical training and experience, Lev was spared hard labor in the mines.\nInstead, he provided medical services to the miners and surrounding community.\nNevertheless, he was not free to leave, and my grandmother could not visit him.\n\nInstead, my grandmother expanded much effort trying to free him.\nShe spoke to many lawyers, and visited many government officials.\nShe was finally told by a well-respected advocate in Kiev, -- \"Child, you just have to wait.\nThere is no case against him, and they will let him out soon.\"\n\n## Aftermath\n\nStalin died in 1953.\nIt was not until 1956 that his successor, Khrushchev, [denounced Stalin](https://www.britannica.com/event/Khrushchevs-secret-speech) and began the \"de-Stalinization\" of the USSR.\nHowever, almost immediately after Stalin's death, many of the political prisoners arrested during his rule were released.\nAmong them, my grandfather Lev.\n\nAfter his release, Lev was restored to his former rights and returned to his previous job.\nHe went on to make many advances in his field.\nAmong them, building one the first pharmacies located inside a hospital, an innovation copied from the USA.\n\nFor his service to the USSR in both military and civilian roles, he was awarded several medals.\nMy mom likes to recount how, when he wanted to call someone in Moscow, he would connect to the operator and just say \"This is Lev, connect me with so and so\" -- an ordeal that was much more difficult for other people.\n\nHowever, though he was liked and respected, he never forgave the USSR for sending him to prison for more than 2 years.\nHe did not join the party, and refused to get involved in any sort of politics.\n", "url": "https://igor.moomers.org/posts/soviet-kgb-stories-pt2", "title": "Soviet KGB Stories II", "summary": "A story of how my grandfather Lev was exiled to the uranium mines.\n", "image": "https://igor.moomers.org/images/uranium.jpg", "date_modified": "2023-09-21T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/self-hosted-link-shortener", "content_html": "\nI embarked on a yak shave so epic, it resulted in me writing an entire URL shortening service in rust.\nI'm calling it `smrs` (get it? \"`sm`all and in `r`u`s`t!), and [here is the github repo for it](https://github.com/igor47/smrs).\nIt's hosted publically, but I don't want to share the link because, from a few minutes of casual reading online, it looks like URL shorteners are frequently abused (see below).\n\n## For the love of God, why?\n\nThe yak shave is that I want to write some microcontroller code, and as I don't really remember any `C`, I figured I'd better just learn embedded `Rust`.\nI cracked open [the embedded Rust book](https://docs.rust-embedded.org/book/), and immediately came across:\n\n> You are comfortable using the Rust Programming Language, and have written, run, and debugged Rust applications on a desktop environment. \n\nI was like, \"Nope, I am not\", and proceeded to the [general-purpose Rust book](https://rust-book.cs.brown.edu/) (I've been reading the Brown-hosted version because I want to take the little embedded quizzes).\nThe book is *really* good, but there's too much reading in between the practical sections, and [I learn by doing](https://psycnet.apa.org/fulltext/2014-55719-001.pdf).\nSo I resuscitated a previous idea of hosting my own link shortener, and here we are.\n\n## Choices\n\nThis project has a really odd mix of new and old technology.\nThe modern approach is to run the project as a single binary which includes an embedded web server.\nThe binary is responsible for serving any static files, and also for generating the dynamic responses.\n\nThis seemed like too much work, and using an existing web server crate seemed like **too little** work.\nSo, I am running the service behind Apache and using good-old [CGI](https://en.wikipedia.org/wiki/Common_Gateway_Interface) for the dynamic content.\nRemember CGI?\nInstead of your application code running as a long-lived process, it's invoked by the web server for each request.\nThe details of the request are placed in the environment, and whatever is written to `stdout` is sent back to the client as the HTTP response.\nIt's probably slower than having the process already running (`fork` and `exec` are slow!), but it lets the program be really simple.\n\nFor storage, I looked at a bunch of options (like `sled` or `leveldb`) but ended up with good-old `sqlite`.\n\nAlso, I'm probably doing a non-conventional thing with sessions.\nI didn't want to implement logins, plus probably for lots of things you don't even care about user-level persistence.\nBut I figured it might be nice, and instead just exposed the user's session ID for them to see.\nIf they want to return to the site later and see their short links, they can just \"log in\" with their session ID.\n\nFor the front-end, I wanted it to be as lightweight as possible.\nI immediately discovered that I need to either have multiple pages, or write an SPA.\nBut for multiple pages, how do I share common elements like a header/footer?\n\nThis is where I learned about Apache's [SSI](https://httpd.apache.org/docs/2.4/howto/ssi.html) (server-side includes).\nI factored my header out into a separate file, and was able to include it in each page with a simple ``.\n\nI still had some javascript to write, and I attempted to just use plain JS with no libraries.\nBut then I discovered [Alpine.js](https://alpinejs.dev/), which is just **so** lightweight and easy to use.\nFor CSS, I used [Skeleton](http://getskeleton.com/) but I'm not super-excited about it.\nThis is because it doesn't have a responsive grid system -- once something is, say, 6 columns, it's **always** 6 columns.\nI'm probably going to migrate this to [Bluma](https://bulma.io/) at some point to fix appearance on intermediate-size screens.\n\n## Deploying\n\nI run my self-hosted services via `docker-compose` on my server, and it was really easy to add this one.\nI set up [my `Dockerfile`](https://github.com/igor47/smrs/blob/master/Dockerfile) for multi-stage builds -- my `dev` target just contains configured Apache.\nI bind-mount my `htdocs` into the container, and iterating on the rust code means building it locally and copying into the container filesystem.\n\nFor production, my final stage builds the release version of the code and generates a container with the `htdocs` baked in.\nI have this container built and tagged via [Github Actions](https://github.com/igor47/smrs/blob/master/.github/workflows/publish.yaml).\nThen, in my `docker-compose`, I can just pull the image from `ghcr.io`.\n\nI ran into trouble because I'm hosting this behind a Cloudflare proxy, and so `traefik` couldn't get an SSL certificate for it.\nI had to add a custom `traefik` config for validating SSL via modifying Cloudflare DNS:\n\n```yaml\n # for zones behind cloudflare proxied DNS, we use the cloudflare dns provider\n # see:\n # https://www.techaddressed.com/tutorials/certbot-cloudflare-reverse-proxy/\n # this relies on credentials in a file on purr. see the `env_file` directive in\n # docker-compose for traefik\n cf:\n acme:\n email: admins@example.org\n storage: /acme/acme-cf.json\n dnsChallenge:\n provider: \"cloudflare\"\n```\n\nI then had to generate a Cloudflare API token with the `Zone.DNS` permission.\nI stored that in a file on my server, and then added it to my `docker-compose` via the `env_file` directive:\n\n```yaml\n env_file:\n - ${STORAGE}/traefik/cloudflare.env\n```\n\n## Link Shortener Criticism\n\nThere's a whole section on [Awesome Self-Hosted](https://awesome-selfhosted.net/index.html) for [URL shorteners](https://awesome-selfhosted.net/tags/url-shorteners.html).\nThis is where I came across [this Wikipedia section](https://en.wikipedia.org/wiki/URL_shortening#Shortcomings) which lists a bunch of criticisms of URL shorteners.\nIn fact, a bunch of the shorteners in the Awesome list have a publically-hosted instance, but every one of those seems dead.\nOthers explicitly say they had to put their public version behind a password or login because of abuse -- for instance, [liteshort](https://git.ikl.sh/132ikl/liteshort) says about their live demo:\n\n> (Unfortunately, I had to restrict creation of shortlinks due to malicious use by bad actors, but you can still see the interface.)\n\nI put mine behind Cloudflare, but I'm still seeing a bunch of nonsense (like wordpress hack attempts) in the request logs.\nSo, I'm keeping the link a \"secret\" for now.\nI might add a password system to create new links if I see a bunch of abuse.\n\n", "url": "https://igor.moomers.org/posts/self-hosted-link-shortener", "title": "A self-hosted URL shortener in Rust", "summary": "I wrote a self-hosted link shortener!\n", "image": "https://igor.moomers.org/images/rusty-scissors.png", "date_modified": "2023-08-30T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/my-rivian-r1s-initial-thoughts", "content_html": "\nI confirmed my pre-order for my Rivian R1S in February 2019.\nIn February 2023, I finally got a delivery window.\nAfter some hassle, I drove away in the vehicle about a month ago.\nAlmost immediately, I went on a 2,500 mile road trip to Colorado through Utah and Nevada.\nI'm at almost 4,000 miles on my odometer.\nSo... how's it going?\n\n## How It Drives\n\nThe Rivian is pretty fun to drive.\nIt's really nice being able to just take on any road.\nWe went to a little hot springs in Colorado that had a really rough, rocky final stretch of road.\nI would have hesitated to drive down that in my Subaru Outback, but with the Rivian there was no concern.\nWe also did several rounds of offroading in Nevada and Utah, and both were **really** fun.\n\nHighway and city driving are also pretty good.\nOne nice thing is that EVs are *really* quiet, which translates into a much more pleasant highway experience.\n\n## Charging\n\nI had some battery and charger anxiety when considering buying an EV.\nThose anxieties are totally gone now.\nThe 300-mile range means that it's actually kind of difficult to be too far from a DC fast charger.\n[PlugShare](https://www.plugshare.com/) helps me be confident that the chargers on the map will actually work.\nI haven't had to wait for a charging station yet.\n\nThe recommended route to Boulder from California would have taken us though Wyoming, which has few EV chargers.\nWe opted to take a slightly longer route through Green River instead.\nKnowing what I know now, I think the Wyoming route would also be okay.\n\nWe were worried that we'd be waiting for the car to charge at our stops.\nIn fact, it's mostly been the other way, with the car being fully charged while S and I are still dithering somewhere.\nOn the drive back, because we were more comfortable with the charging infrastructure, we would stop for a quick bio break while the car gained 20% to 30% of charge, and then we'd head to the next charger.\nIt's much nicer to hang out at most chargers than at gas stations (though we **really** miss windshield cleaning supplies at most charging stations).\n\nMy body is much happier with more, longer stops and opportunities to walk around and stretch while the car is charging.\n\n## Camping\n\nCamping in the Rivian is much nicer than in my Subaru.\nIt's much more roomy, and has fewer hard edges with the seats down.\nThe glass roof is also quite lovely.\n\n\n\nThere's more storage space (the frunk!), so we didn't need to bring a cargo rack.\nThe door opens in two halves, and I really enjoy sleeping with the bottom half closed.\nIt feels like my bed is less likely to slide out of the car, and we can still keep the top half open for a nice breeze.\n\nI really like all the camping settings in software.\nFor instance, self-leveling is better than having to look for correct-sized rocks to put under the car.\nOn the other hand, I've found the software quite buggy (see below).\nOur first attempt to use self-leveling in Nevada resulted in the car constantly adjusting it's height until the compressor overheated, and then we just had to wait for it to cool down and try again.\nOn another occasion in Utah, I reset self-leveling while packing the car, and then when I got in it wasn't reset and I had to reset it again.\n\nWhile I appreciate all the attempts to control lighting while camping, they, too, are very buggy.\nFor instance, there's a \"keep screens off\" setting, which claims you'll need to press the brake to turn the screens back on.\nIn fact, the screens come back on when you touch them.\nThe light controls are sometimes-broken and sometimes-buggy.\nFor instance, the tail gate light just keeps turning on whenever I open a door, despite me being in camp courtesy mode and also explicitly turning that light off several times.\nTo avoid that bright light coming on whenever I exit the car to pee, I've resorted to just setting the car to \"do not use energy\" mode.\nIt's nice that this exists -- but it also means that all the other lights don't work.\n\nFinally, it seems like even in \"do not use energy\" mode, the windows still work.\nThis is great -- in my Subie, I would have to insert the key and turn the car on to get fresh air or keep out bugs/the cold.\nHowever, at least once, the windows *do not* work in that mode -- another bug?\n\n## Driver+\n\nI'm used to the adaptive cruise control (ACC) from my Subaru.\nThe Rivian's Driver+ adds more effective lane-keeping.\nThis is great when it works, mostly on straight interstate highways.\nIt does not work on any roads that are not the interstate.\nIt turns off when you change lanes.\nIt turns off in less-than-ideal visibility, like when it's raining (\"camera blurry\").\nIt turns off for some, but not most, tunnels.\nIt also sometimes turns off for no reason, at the oddest time, with a loud beep, and then you swerve and catch the car before it smashes into something.\n\nPart of the reason we didn't bring the cargo rack is that using a \"rear accessory\" turns off all self-driving features, including good-old adaptive cruise control.\nThe Subaru still allowed me to use ACC with my cargo rack plugged in (it has brake and turn lights), so on a longer road trip with more outdoor/camping time, I would be pretty annoyed about that.\n\nA common complaint on forums is about how Driver+ mutes your music for a moment whenever anything changes.\nThis is indeed pretty annoying.\nFinally, I tried their lane assist, which is not full lane keeping, but does nudge you back into the lane if you depart it.\nThis was pretty aggressive and I turned it off.\nThey claim to have made it better in the recent update, but I haven't tested it yet.\n\n## The Nav\n\nThe screens in this car are trying to kill me.\nThey're so big and shiny and full of buttons that change position.\nAs I navigate this 4-ton monstrosity down the public roadways, the screens are telling me, \"Look at us, not the road!\"\n\nThe in-car nav system is basic.\nYou **have** to use it if you want to keep track of your state of charge, or have the car pre-condition the battery.\nBut it barely knows about traffic.\nIt sometimes doesn't work (like, it won't actually give you directions, or it will just sit there trying to compute the route).\nYou can't just tap a destination and have it route you there.\nYou can't add side trips (any new destination replaces the previous one).\nIt's always routing me to the back of any business I try to go to.\nIt includes some non-existent chargers, and excludes some existing ones.\nIt doesn't know about the state of most chargers (e.g, Electrify America ones, which are most common on road trips).\nIt doesn't know about speed traps or construction.\n\nI installed a phone holder on my dash, but honestly having 3 screens to look at is too many, and so I end up just using the car nav system while disliking it.\nMuch has been said about Android Auto and how Rivian is not going to add it.\nI think this is a customer-hostile move -- I just don't see how it benefits the customers, only the company's own dreams of world domination through software.\n\n## Music\n\nI have a version of the car with the Meridian-branded sound system, and it's ... okay.\nI mean, it sounds fine, somewhat better than the Subaru, but mostly I think because the car is pretty quiet.\nThe bluetooth in the car seems fairly reliable, better than the Subaru.\nAudio books work well in the `voice` EQ preset, and I tend to use the `rock` preset for all music.\n\nI also use the in-car version of Spotify, which is barely passable.\nBasic things -- for example, searching for a song, and then adding it to the current playlist -- are not possible.\nBut it's nice that there's music without having to connect my phone to the car.\n\n## Camp Speaker\n\nThis thing is maddening, and I honestly wish it didn't exist, rather than existing in it's current, broken state.\nIt sometimes works okay, and sometimes it refuses to connect to my phone.\nIt's so finicky and frustrating that S had to prevent me from just flinging it into the forest.\n\nOne time, I was having some people over, and I wanted to put some music on the camp speaker.\nI proceeded to spend 20 minutes trying to get the speaker to stay connected to my phone before finally admitting defeat.\nIt did this thing where it would *almost* connect, like just for a moment, and then disconnect again, that was close enough to working that I Just. Kept. Messing. With. It.\nOn another occasion, I finally got connected and was playing music, and then it just stopped working for no reason and I couldn't get it to work again.\nOn yet a few more occasions, it powered on and made it's loud boot-up noises while we were sleeping in the car and the speaker was inserted into it's speaker-slot.\nThis was alarming and embarrassing (because there were some people sleeping in the car next to us).\n\nIn short, I hate the camp speaker.\n\n## Access\n\nI like having the app as a backup way to get into the car.\nBut I would prefer to use the key fob, which unfortunately is the worst.\nFirst, it has four identically-shaped, black-on-black buttons.\nAfter a month, I still don't know which one does what.\nGood look trying to figure out which side of the fob is even the one with the buttons in the dark.\n\nOnce you figure out what button to use -- good luck getting the car to respond.\nI just love standing in the rain with my friend and her 5-year-old, all of us getting wet while I repeatedly hit the unlock button while the car *thinks about something*.\nS also pointed out that this makes her feel unsafe.\nImagine a lone woman walking to her car on a dark street -- she wants that car to freakin' unlock!\n\nI don't understand why this could work instantly in my Subaru, but takes sometimes a minute on my Rivian.\nI bet it has something to do with the software.\nSpeaking of which...\n\n## The Software\n\nOkay, so, I'm a software guy.\nThis car is chock full of software.\nAnd -- it's pretty bad.\nIt's buggy as all hell.\n\nI gave some examples already, such as the tailgate light or the display not staying off, or the nav being unreliable.\nOther examples:\n* all of the lights will just come on for no reason\n* the lights button on the rear screen and the front screen are not aware of each other\n* the car forgets about it's leveling state\n* the bluetooth will just randomly turn back on, even after it's been turned off\n* sometimes battery pre-conditioning doesn't activate automatically; no way to do it manually\n* sometimes the car will refuse to charge, and you have to hard-reboot it\n\nOh, Rivian support recommends a hard-reboot for most troubleshooting.\nI was worried enough about the update [bricking my car](https://www.reddit.com/r/Rivian/comments/136y8gd/r1s_bricked_after_accepting_update_last_night/) that I avoided doing it until we returned from our road trip.\n\nI'm honestly worried and annoyed about the state of the software.\nProgress seems slow -- for instance, a major revision between January and May in Rivian software-land was hiding the trip odometer deeper into a settings sub-menu, despite people on forums asking for trip odometer to be *more* accessible.\nIt's not clear how to report software issues.\nI have been using the `Service` requests feature in the app, but clearly software issues are not service items.\nAre these reports going anywhere?\nI don't know.\n\nThere is a Rivian employee occasionally on Reddit, and people leave comments like \"I really hope this person sees this comment\".\nPeople repeatedly report the same software issue over and over, and there's no way to know if Rivian already knows about it or is planning to fix it or what.\n\nI guess I bought this very expensive beta piece of software, and I was kind of resigned to the early user experience and helping to improve the product.\nBut actually, with the other half-finished software projects I use, there's public issue trackers and road maps.\nRivian has none of that.\nThey're not telling whether anyone is even hearing me, much less if they plan to fix things.\nThe end result is that I'm much more frustrated than I anticipated.\nOn the basis of the software bugs alone, I would NOT recommend the Rivian to most people.\n\n## Support\n\nWhen we picked up the car, we noticed a problem with the head liner.\nThere was no availability for an appointment at the service center for several weeks.\nSo, the car is finally going in to get that fixed the week after next.\nThis might be a blessing in disguise, since I've found a bunch of other issues that can be fixed in the same visit (dead USB-C port, broken floor matt pin, inoperable lighting, etc...).\nThough, I guess it would be better if the car *hadn't* come with a bunch of issues?\n\nHowever, I'm also scared.\nPeople are saying that [the service centers are chaotic and overwhelmed](https://www.reddit.com/r/Rivian/comments/13l4nci/rivian_please_work_on_your_service_centers/).\nAlso, it seems like even minor accidents can result in [huge repair bills](https://www.theautopian.com/heres-why-that-rivian-r1t-repair-cost-42000-after-just-a-minor-fender-bender/).\nI'm worried that, if I need immediate maintenance, I might be out of luck.\nThankfully, this is an adventure mobile and I don't critically need it, but it would suck to miss a trip.\n\n## Minor Peeves\n\nThe car goes out of it's way to hide kilowatts from you -- range is measured in `%` or miles.\nIt does show efficiency in miles per kWh, but not how much kWh are left in the battery.\nI would really like to connect the speed of the charger I'm pulling up to -- invariably in kWh -- to the capacity of the battery, which is a mystery and nowhere in the UI.\nI would also *love* to see a live indication of how much power the car is using while camping.\n\nThere is no cruise control resume.\nIf you brake because a car swerved into your lane, or because you stopped at at a sign on a long stretch of highway, you'll have to re-set your previous cruise control speed manually.\n\nThe camera button is hidden in an overflow menu.\nIf you need help navigating into a tight parking spot, you'll have to pause and click around mid-park.\n\nThe windshield wipers are kind of hard to use manually.\nThe control is small, and the first tap only shows you the current setting, so you always need at least two.\nI would love to just leave it on auto, but it's often way too fast in low-rain conditions.\n\nThe AC controls decide on their own whether the car is heating or cooling.\nI really miss just having a fan blow outside air.\nThis would be especially nice while camping, where I don't want to use power for heat or AC, but a little extra airflow would be lovely (and help keep bugs off me!).\n\n## Summing Up\n\nI am definitely really enjoying having an EV.\nIt's also really fun to have a very capable off-road vehicle.\nOn the other hand, I'm finding it frustrating to be a Rivian early-adopter.\nThe car is buggy, and there's not really a good communication channel to the company to help resolve the bugs.\nI fear that I'll be stuck living with these bugs forever.\n\nHopefully, in the next year, Rivian will improve the quality of the software (though I think some things, like Android Auto, are never going to happen).\nThey might also add features I'm really hoping for, such as V2H/V2G.\nI'm also excited about all of the other electric SUVs and adventure vehicles coming onto the market in the next few years.\nHopefully, there will be less-buggy, more-polished alternatives to the Rivian available in the next few years, and those might be worth waiting for.\n\nFinally, I'm also just pretty scared of the high-software closed-source proprietary-nonsense vehicle future that we're entering.\nWhat happens when Rivian burns through it's cash and runs out of money?\nWill I be left with an expensive brick?\nWhy does my car need always-on internet connectivity?\nWho are they selling my location data to, or sharing it with?\nI'm sad that the EV transition is also being used as an opportunity to take control away from vehicle owners and transfer it to car companies and their big-business allies (in Rivian's case, Amazon).\n\nI really wish there was a car company that was transparent and consumer-friendly.\nAlas, I don't think that's Rivian.\n", "url": "https://igor.moomers.org/posts/my-rivian-r1s-initial-thoughts", "title": "My Rivian R1S: Initial Thoughts", "summary": "I picked up my Rivian R1S just over a month ago; how is it going?\n", "image": "https://igor.moomers.org/images/rivian-in-the-wild.jpg", "date_modified": "2023-05-19T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/purchase-allocation-via-graph", "content_html": "\n**Note**: This is cross-posted to the [Recoolit blog](https://www.recoolit.com/post/purchase-allocations-eng).\n\nWhen you [buy carbon credits from Recoolit](https://www.recoolit.com/buy), you are buying a specific amount of prevented atmospheric warming.\nWe prevent warming by preventing the release of refrigerants into the atmosphere.\n(Note: if you want to learn more about how refrigerants cause warming, check out [our post on refrigerants](/posts/refrigerants-what-are-they).)\nOur purchase receipts are designed to be transparent -- you see exactly how much warming you are preventing, and exactly how.\nThis post explains the technical details of how we create this transparency.\n\n## Brief Overview of Recoolit\n\nWhen refrigerators, air conditioners, or other kinds of heat pumps reach end-of-life or need maintenance, the refrigerants inside need to be removed from the system.\nThis is because refrigerant is at high pressure inside the system, and needs to be depressurized before the system can be serviced safely.\nIt is common for refrigerants to be vented into the atmosphere during this process.\nRecoolit provides technicians with the tools, know-how, and incentives to capture these waste gasses instead of releasing them.\nThen, we destroy the captured gasses in a high-temperature incinerator, permanently preventing their release into the atmosphere.\n\nOur main mechanism for incentivizing refrigerant capture is to pay technicians for the refrigerants they capture.\nWe also have to pay for the cost of destroying the refrigerants, including getting the destruction facility inspected and certified to international standards.\nFinally, we have to cover our operational expenses.\nThis includes buying and maintaining the pumps and cylinders that we use to capture and store refrigerants.\nWe maintain several depots, where technicians can borrow the equipment needed for recovery.\nFinally, we pay for a warehouse where we store refrigerants before they are destroyed.\n\nWe cover all of these costs by selling carbon credits to individuals and organizations that want to offset their carbon emissions.\n\n## Why Transparency?\n\nThe world has almost no way to pay for pollution remediation.\nSometimes, governments will force polluters to pay for the cost of cleaning up their pollution.\nOther times, governments will directly pay for cleanup using tax dollars, especially when the pollution is a public health hazard and there is no obvious responsible party who can be forced to tackle the cost.\n\nSo, even with the growing awareness that climate change is a big, looming problem, there are too few ways to get money to organizations that are tackling the issue.\nThe voluntary carbon credit markets -- where individuals and companies pay for carbon credits out of a sense of social responsibility, and not for any regulatory reason -- are one of the few ways to pay for climate change remediation.\n\nHowever, the voluntary carbon credit markets have been a bit of a mess.\nThere are no international agreements or standards on how to quantify the impact of carbon credits.\nA few private organizations have stepped in to fill this gap, but their standards are not universally accepted.\nFinally, some of the largest private organizations -- known as registries -- have faced controversy.\nFor instance, Verra, one of the largest registries, [has been criticized](https://www.theguardian.com/environment/2023/jan/18/revealed-forest-carbon-offsets-biggest-provider-worthless-verra-aoe) for allowing carbon credits to be sold for projects that were already underway, and for projects that were not actually preventing warming.\n\nFor these reasons, Recoolit's founder Louis was determined for the company to be as transparent as possible from day one.\nWe collect detailed data on every step of our operational process.\nWhen you make a purchase, we show you all of the data we've collected that pertains to the molecules that went into your purchase.\nFinally, we show as much data as possible on [our public registry](https://registry.recoolit.com/registry), so that anyone can see exactly what we are doing.\n\n## What Is Our Data?\n\nEvery Recoolit carbon credit begins with a recovery.\nThis is where a technician captures refrigerants from a refrigerator, air conditioner, or other heat pump.\nAt this step, we collect photos of the equipment that's being serviced, the reason for the refrigerant recovery, the amount of gas recovered, and the type of gas recovered (though we don't always know the exact type of gas at this point).\n\nNext, technicians return the cylinder used for the recovery to one of our depots.\nWe verify the amount of gas recovered, and we also test the gas using a gas analyzer.\nWe pay the technician for the amount of gas they collected.\nThis payment compensates the technician for the time and effort they spent performing the recovery.\n\nBecause we want to return the smaller recovery cylinders back into the field, we will often consolidate the gas from multiple recovery cylinders into a larger storage cylinder.\nWe cannot mix different types of refrigerants, so we have to keep track of the type of gas in each cylinder.\nEvery time gas is transferred, we keep detailed records on the source and destination cylinders and weights.\nSome small amount of gas is always lost during transfers, and the losses are not included in the carbon credits we sell.\n\nNext, we transport the gas to our destruction facility.\nEvery time we transport gas, we weigh and test the cylinders at both ends.\nWe maintain a chain of custody for the cylinders at all times, using signed transport manifests.\nSome of the refrigerants we transport are becoming expensive, because they are no longer allowed to be produced under internal agreements.\nOur procedures protect against loss or theft of refrigerants during transport.\n\nFinally, our refrigerants go through the destruction process.\nFirst, we take a sample of each cylinder that has arrived at the destruction facility.\nThe sample is lab-tested under rigorous standards, to confirm the exact makeup of the contents of the cylinder.\nNext, the cylinder is hooked up to a high-temperature incinerator.\nIn Indonesia, we partner with cement kiln operators, because their facilities reach the high temperatures needed to destroy refrigerants and need only minimal modifications to do so.\n\nAfter destruction, the cylinders are shipped back to us.\nWe vacuum-test the cylinders to make sure they're not leaking, and use them for future recoveries or consolidations.\n\n## Building the transfer graph\n\nWhen you buy a carbon credit from Recoolit, you are buying a specific quantity of a specific gas that was destroyed.\nIn order to show you all of the data that went into your destruction, we need to trace the path of the gas from the recovery to the destruction.\nWe call this data structure the \"transfer graph\", and it is the core of our transparency system.\n\nThe transfer graph is a directed acyclic graph (DAG).\nIn this graph, the edges are transfers from a source to a destination node.\nEach edge has a weight, which is the amount of gas transferred, as well as a gas type.\n\nBecause cylinders are reused, the nodes are actually a specific cylinder ID during a specific time interval.\nA node is created when gas is first transferred into it, and \"closes\" when all of the gas is transferred out and we vacuum out the cylinder.\nA subsequent transfer into the same cylinder ID would create a new node.\n\nEach node can have multiple incoming and also outgoing edges.\nThis is because we sometimes do partial transfers.\nFinally, each node can have a series of \"events\" associated with it.\nEvents include things like \"the gas was tested\", \"the cylinder was transported\", or \"the cylinder was weighed\".\n\n## An example\n\nThis might be easier with an example, so let's use some real data from our public registry.\nI bought some credits from Recoolit, and [here is my receipt for that purchase](https://registry.recoolit.com/purchases/f436f5ca-a6fe-49c4-b10c-f4e46cafcb8d).\nThis is a view of the same data in our internal system:\n\n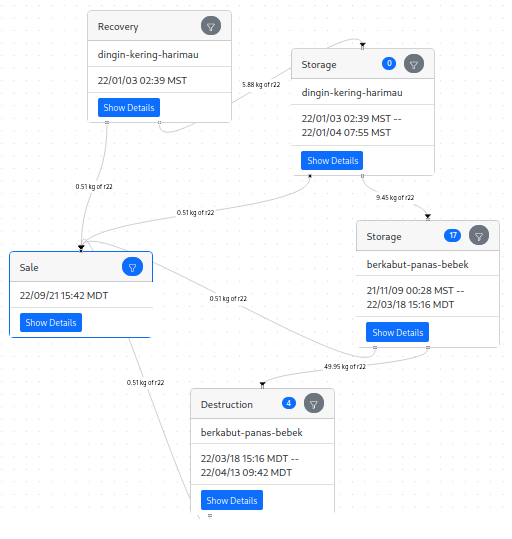\n\nTo allocate this purchase, we first look through all of our destructions to find one that has enough gas to cover the purchase.\nWe might need to combine multiple destructions to cover the purchase.\nIn this case, we find that we destroyed about 50kg of R-22 from cylinder `berkabut-panas-bebek`.\nR-22 is such a high-GWP refrigerant that only 511 grams of it were needed to cover my purchase of 1 tonne of CO2e.\n\nNext, we do a depth-first search through the graph, starting at the destruction node, and looking for a path that has enough gas to cover the purchase.\nWe see that about 10 kg of R-22 arrived in `berkabut-panas-bebek` from `dingin-kering-harimau`, so we allocate 511 grams of that 10kg.\nFinally, we see that 5.8 kg of R-22 was recovered directly into `dingin-kering-harimau`, so we allocate 511 grams of that 5.8kg.\n\nThis was a fairly easy case, as it only involved a single trajectory through the graph.\nHere's an example of a more complicated sale, which involved multiple kinds of gas allocated through multiple destructions:\n\n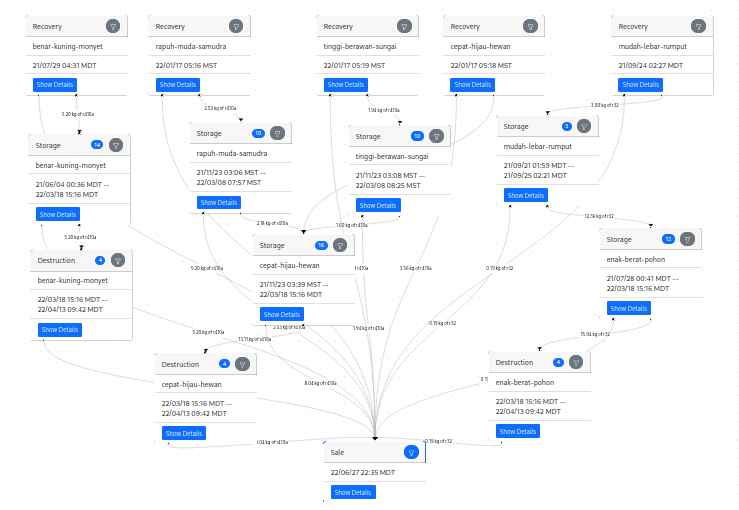\n\nIn this case, the purchase of 30 tonnes of CO2e was covered by 3 different destructions.\nWe destroyed 13235 grams of R-410a and 193 grams of R-32 to cover this purchase, and these gasses were recovered by two technicians on 3 different occasions.\nThree of the five recoveries were on the same day into three different cylinders, indicating a large recovery job that filled up multiple cylinders!\n\n## Allocating purchases\n\nWe allocate purchases using a depth-first search through the graph, starting at the destruction node.\nEvery time we find a node that has enough gas to cover the purchase, we recursively look through the source nodes.\nThe recursion terminates at a recovery node.\nWe then propagate the list back up through the stack, allocating the purchase to each node in the path.\n\nAllocating the purchase means creating edges.\nFor each purchase, we create a `sale` node in the graph.\nFor each node that contributes gas to the purchase, we create a `sale` edge, from the source node to the `sale` node.\nTo find all the nodes involved in allocating a sale, we look for all nodes connected to the `sale` node through a `sale` edge.\n\nEach `sale` edge includes the amount of gas that was allocated to the sale.\nTo figure out if a node still has enough gas to cover the sale, we subtract the sum of all `sale` edges from the weight of the node's outgoing transfer edge.\n\n## Formatting for display\n\nWe've already discussed all of the data we collect during operations to enable this kind of transparency.\nYou can now also know how our system allocates your purchase to destructions and recoveries.\nThe final piece is presenting this data in a way that is easy to understand.\n\nIn your receipt, we show you a path-decomposed version of the transfer graph.\nA path is a linked list of edges and nodes, starting at a recovery and ending at a destruction.\nHowever, in your purchase subgraph, a single node or edge might be involved in multiple paths.\nWhen we do the decomposition, we clone the shared nodes and edges, so that each path has its own copy.\nHere's an example of a non-decomposed graph:\n\n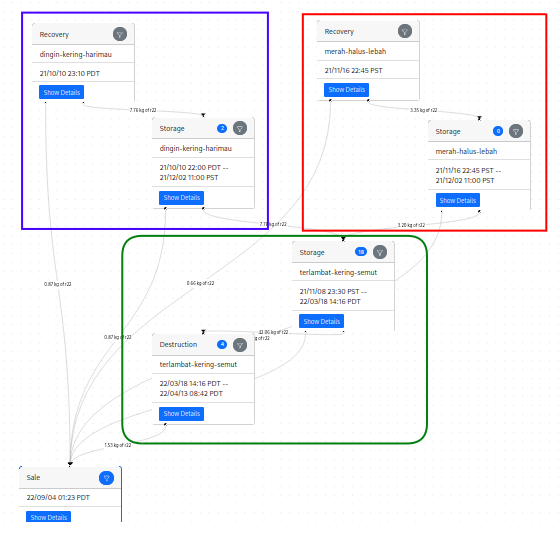\n\nYou can see that this includes two recoveries -- one in the blue box, and one in the red box.\nThe green box includes a consolidation and destruction nodes that are shared between the two paths.\nWhen we display it, it would look more like this:\n\n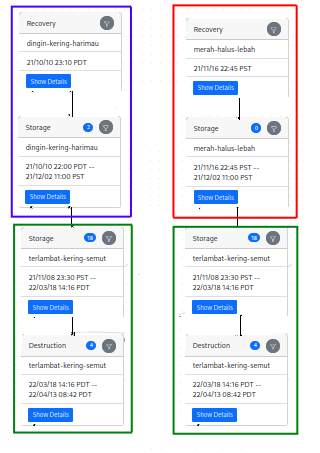\n\nThere are two paths in this graph -- the one on the left, and the one on the right -- and the nodes in green are duplicated between the two paths.\nHere's how the same data might look in your purchase receipt:\n\n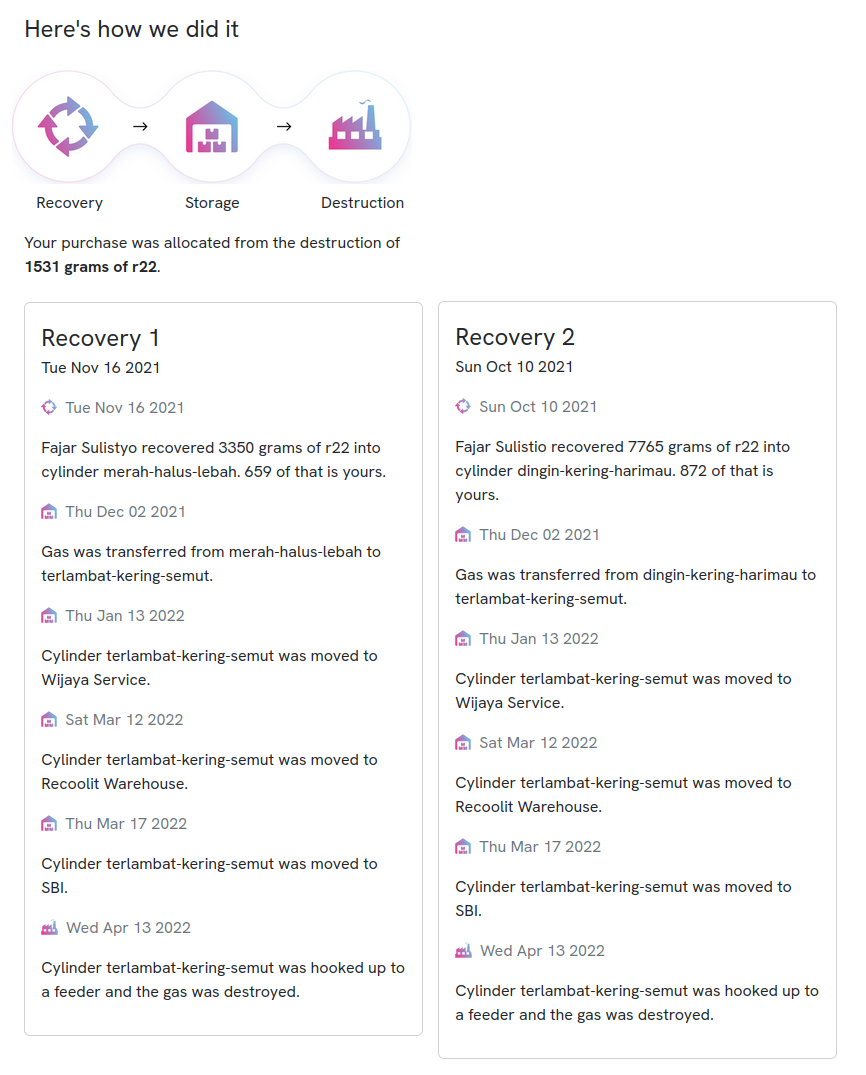\n\nDoing this is surprisingly non-trivial because it's not clear, just from the subgraph, how many paths through a particular node there are.\nTo make it easier, we actually keep track of the paths when we construct the graph.\nEach time we begin trying to allocate gas from a destruction, we generate a path identifier.\nWhen we find a path that works, we store the path identifier in the `sale` edges that track the allocated purchase.\nThis means that a node might actually have multiple edges connecting it to a `sale` node, each with a different path identifier.\n\n## Wrapping up\n\nAs you can see, we've put a lot of thought into how to make our data as transparent as possible.\nOur goal is to create the highest-quality carbon credits, with the greatest possible assurance to buyers that their purchase is actually making a difference.\nIf you like what we're doing here, and want to support us, we urge you again to [buy some carbon credits](https://registry.recoolit.com/buy)!\n", "url": "https://igor.moomers.org/posts/purchase-allocation-via-graph", "title": "Purchase Allocation via Graph", "summary": "Recoolit is focused on transparency, and every purchase is allocated to a specific molecules recovered in the field. This post describes how we do that.\n", "image": "https://igor.moomers.org/images/transfer-graph-2.png", "date_modified": "2023-05-11T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/refrigerants-what-are-they", "content_html": "\n**Note**: This is cross-posted to the [Recoolit blog](https://www.recoolit.com/post/refrigerants-what-are-they).\n\nAt [Recoolit](https://www.recoolit.com), our mission is to reduce climate impact by collecting and destroying waste refrigerants.\nThis mission is often unclear to people who aren't familiar with the refrigeration industry.\nWe often hear questions like, \"What are refrigerants?\" or \"Why are refrigerants a problem?\"\nWe've skipped over such questions on our [explainer page](https://www.recoolit.com/our-work) because they're quite technical, and we don't want to overwhelm our customers.\nThis post is for those special nerdy few who want to know all the gory details!\n\n## Heat pumps -- How do they work?\n\nRefrigerators and air conditioners are all a type of heat pump -- a device that moves heat from one location to another.\nThey do this by means of a fluid that is pumped through a closed loop.\n\nFirst, the fluid is compressed, which causes it to heat up, turn into a gas, and become much warmer than the surrounding air.\nNext, the gas is pumped through a heat exchanger -- like a radiator on a car -- which results in the gas becoming cooler while the surrounding air becomes warmer.\nIn a heat pump on \"warming\" mode, this heat exchanger is located inside a building or room, and this warming is the desired effect.\n\nThe gas is then pumped to a second heat exchanger, where it is allowed to expand, turning it back into a liquid.\nThe expansion cools the fluid.\nIt's then pumped through a second heat exchanger, where it becomes warmer, while the air around it becomes cooler.\nIn a heat pump on \"cooling\" mode, this second heat exchanger is inside the refrigerator, freezer, or too-warm room or building.\n\nThe fluid is then pumped back to the compressor, and the cycle begins again.\nMechanically, all heat pumps rely on just these few components -- a compressor, pumps, heat exchangers, and the fluid -- sometimes a gas, sometimes a liquid -- that runs between them.\nPhysically, this process relies on just a few basic principles of nature -- the ideal gas law, plus the laws of thermodynamics.\n\n## What are refrigerants?\n\nRefrigerants are the fluid used inside heat pumps to move heat from one place to another.\nThere are many considerations when picking a substance to use as a refrigerant.\nFor instance, a common early refrigerant was ammonia (R-717).\nAmmonia boils at a low temperature, which makes it easy to turn into a gas.\nIt does not freeze until a very low temperature, so there's no risk of it freezing inside the heat pump during the expansion phase.\nAnd it has a fairly high specific heat, which means that it can absorb and release a lot of heat.\n\nUnfortunately, ammonia is highly toxic and corrosive.\nOther early refrigerants, such as sulfur dioxide (R-764) and methyl chloride (R-40), were also toxic.\nTo avoid the safety issues associated with early refrigerants, scientists began experimenting with other substances.\nIn 1928, Thomas Midgley, Jr. invented the first chlorofluorocarbon (CFC) refrigerant, which was marketed by DuPont as Freon-12 (R-12).\nR-12 was cheap to produce, non-toxic, non-flammable, non-corrosive, and it had a low boiling point and a high specific heat.\nThese properties led to R-12 becoming the most popular refrigerant in the world, with production peaking at over 1 billion tons per year in the 1980s.\n\n## The Montreal Protocol\n\nWhen searching for safer replacements to early refrigerants, scientists looked for substances which were highly stable, since stable substances pose less of a health risk to humans.\nThis made R-12 an attractive choice, since it was highly stable and non-toxic.\nHowever, this stability also proved to be a problem.\nIn the 1970s, scientists studying the ultimate fate of CFCs like R-12 discovered that these gasses could make their way up to the stratosphere.\nThere, they could be broken down by ultraviolet radiation, releasing chlorine atoms (the first C in CFC and HCFC).\nThe chlorine would then react with, and destroy, atmospheric ozone.\n\nIn response to these findings, in 1987 the international community adopted the Montreal Protocol on Substances that Deplete the Ozone Layer.\nThe agreement was initially signed by 46 countries, and has since been ratified by 198 parties, including all member states of the United Nations.\nIt sets out a schedule for the phase-out of the production and consumption of ozone-depleting substances (ODSs), including CFCs like R-12 and HCFCs like R-22.\n\nThe phase-out schedule differed for different substances and in different places.\nFor instance, R-12 was phased out in developed countries in 1996, and in developing countries in 2010.\nMeanwhile, R-22, an HCFC common in home and commercial heat pumps, was phased out in developed countries in 2010, but it continues to be in-use in developing countries until 2030.\n\n## GWP and the Kigali Amendment\n\nIf you recall, one of the properties of a good refrigerant is its ability to absorb and release heat.\nRefrigerants continue to play this role even after they've been released into the atmosphere.\nIn particular, they absorb and release heat in the form of infrared radiation, which is the same type of radiation that is absorbed and released by greenhouse gasses like carbon dioxide and methane.\n\nThe heat-trapping ability of a greenhouse gas is measured by its global warming potential (GWP).\nThe standard basis of comparison is the most common greenhouse gas, carbon dioxide (CO2), which has a GWP of 1.\nThe GWP of Freon, or R-12, is 10,900.\nThis means that, released into the atmosphere, R-12 traps 10,900 times as much heat as an equivalent amount of CO2.\n\nCFCs and HCFCs phased out under the Montreal protocol were often replaced by hydrofluorocarbons, which have many of the desirable properties of a refrigerant, but without the ozone-destroying chlorine.\nFor example, an HFC called R-134a is a common replacement for R-12 in automotive air conditioners.\nHowever, R-134a has a GWP of 1,430 -- much less than R-12, but still substantially heat-trapping.\n\nWhen the Montreal protocol was adopted in 1987, the focus was on the ozone-depleting properties of CFCs and HCFCs.\nHowever, as the world began to phase-out these substances, it became clear that their global warming potential was also a problem.\nIn response, in 2016 the international community adopted the Kigali Amendment to the Montreal Protocol.\nThe Kigali amendment is meant to prevent additional global warming from refrigeration by phasing-out the production and consumption of hydrofluorocarbons (HFCs), which are the most common replacements for CFCs and HCFCs.\nThe amendment has, so far, been ratified by [148 parties](https://ozone.unep.org/all-ratifications). \n\nLike the Montreal Protocol, the Kigali Amendment sets out a schedule for the phase-out of HFCs, but this schedule differs from place to place.\nFor instance, for R-3\nIn the developed world, the phase-out began in 2019, and is scheduled to complete by 2036.\nIn the developing world, however, the phase-out is not scheduled to end until 2045, with some countries receiving additional extensions to 2047 or later.\n\n## How Recoolit Fits In\n\nRefrigerant pollution is a major global problem, and the world is working hard to solve it.\nHowever, as you can see, even the phase-out of ozone-depleting substances like R-22 will not be complete until 2030.\nWith high-GWP HFCs like R-134a, the process has barely begun, and will last for decades.\n\nWhat do we do in the meantime?\nThis is where Recoolit comes in.\nWhile the world works to phase out harmful refrigerants, we can work to reduce the amount of refrigerant pollution that is released into the atmosphere.\n\nCertainly, some of this release is accidental or the result of equipment malfunction.\nHowever, a significant portion of refrigerant pollution is the result of intentional venting.\nThis is because, without Recoolit, technicians simply have no other way to dispose of refrigerant properly.\nEven well-intentioned technicians, who are concerned about pollution and environmental impacts, have no other choice when a system must be drained for maintenance or repair.\nWe've seen technicians vent refrigerant through a hose inserted into a bucket of water, in the (mistaken) belief that this will somehow \"scrub\" the refrigerant.\n\nAdditionally, the process of recovering refrigerant is time-consuming and expensive.\nThe international protocols do not provide any funding for the transition to cleaner refrigerants, or to mitigate the damage from refrigerant pollution.\nThis is where you come in.\nNow that you know about the problem, you can help us solve it.\nFund our work by [buying our carbon credits](https://registry.recoolit.com/buy).\nTell your friends and colleagues about the problem, and about our solution.\n", "url": "https://igor.moomers.org/posts/refrigerants-what-are-they", "title": "Refrigerants: What Are They?", "summary": "Recoolit prevents global warming by collecting and destroying refrigerants. But when even are refrigerants? Read to find out what refrigerants do, the different kinds that exist, why they can be so concerning, and how the world has managed the risk.\n", "image": "https://igor.moomers.org/images/refrigerants.jpg", "date_modified": "2023-05-08T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/open-letter-gpe", "content_html": "\nIn Cory Doctorow's book [Down and Out in the Magic Kingdom](https://bookshop.org/books/down-and-out-in-the-magic-kingdom/9781250196385), the main character (Jules) has this to say about himself:\n\n> [my compulsion] was Beating The Crowd, finding the path of least resistance, filling the gaps, guessing the short queue, dodging the traffic, changing lanes with a whisper to spare -- moving with precision and grace and, above all, _expedience_.\n> I spied a queue ... that was slightly longer than the others, but I joined it and ticced nervously as I watched my progress relative to the other spots I could've chosen.\n> I was borne out, a positive omen for a wait-free World, and I was sauntering down Main Street, USA long before my ferrymates.\n\nReading this passage, I realized that I was not alone in my weird obsession.\nI hate lines, the waiting in of, and like Jules I will obsessively attempt to pick the shortest queue to optimize my wait time.\n\nAs you can imagine, Burning Man, with it's notorious entry and exodus lines, is a kind of special torture for me.\nI struggle constantly to remain patient and silence my overeager mind as it attempts to compute my rate of progress relative to my line-mates and my destination.\nI become short and distracted with my car mates, and annoyed at the perceived inefficiencies in the system.\n\nIn order to channel my frustration into a productive direction, back in 2012 I joined the Gate, Perimeter, and Exodus (GPE) department.\nIn the decade since, I've worked just about every position in the department -- apex, airport, lanes, perimeter, and this year I did a stint in the Traffic Operations Center (TOC).\nI worked enough shifts in 2019 for a staff-priced ticket, and enough this year for a staff credential for my next burn.\n\nTo some extent, joining the department (as well as simply becoming a decade older and a little bit more patient) has helped me deal entry/exit crawl.\nWhen the line totally stops moving at 6 pm, I know that there's a shift change, and we'll get moving soon, and I can reassure people around me about this.\nWhat I hoped for, however, was a sense that there's some giant master plan that's helping to move me out of a 10-hour traffic jam as quickly as possible.\nThis sense continues to elude me, and is the reason I'm writing this open letter.\n\nI do not mean to throw shade on any people in the department.\nI understand first-hand how difficult these shifts are, standing out in a white-out in 100+ degree heat, breathing dust and exhaust, dealing with cranky and cantankerous burners while trying not to get crushed by traffic.\nI also understand the difficulty that the leaders of the department have, doing this thankless job in exchange for meal pogs and t-shirts, trying to take care of their volunteers while balancing the demands of the org, various state agencies, and the forces of pure chaos.\nBut I cannot help but get the sense that something is not working quite right.\nI am 200% open to the possibility that, actually, everything is going as well as possible, and it's just that my spidey sense is off here.\nI know that when other department members express concerns on the gate list, they sometimes get (vehemently) dismissed as \"armchair quarterbacks\" who, because they weren't working that specific shift or that specific role, have no right to an opinion.\nBut in this case, I think it's a communication problem.\nIf even long-time department volunteers (including this one) are frustrated and confused by the operation of the department, what of the participants?\nThese are the people who, after being stuck in a 10-hour traffic jam for inscrutable reasons, unload their anger on the front-line Exodus volunteers.\nEveryone here deserves better -- and even if this is *just* a communication problem, that's still a real problem that, I believe, demands attention.\n\n## Entry\n\nMy entry into Burning Man was more than 3 hours long -- on Wednesday pre-event!\nAs others have noted on the gate list, the second and third lines from the left on the way in merged right before apex, meaning those two lines moved half as fast as the other lines.\nI attempted to reassure my car mate for almost an hour that this must be an illusion, and that no line moves faster through Apex than any other line, but my poor choice of lanes cost me a lot of extra wait time, and anxiety that we would miss our camp's placers for the night and would have to sleep in our truck instead of setting up camp.\nThe department doesn't want participants changing lanes, because it messes up the cone placement.\nThe best way to prevent lane-jumping is to make sure the lanes are actually fair!\n\nNext, I had to pick up my staff credential from the box office.\nOn the way out of the Will-Call lot, we again had a massive line stretching back into the lot.\nTwo volunteers at the front were letting cars out of Will-Call, only into the two rightmost lanes, which Apex was also using.\nThis resulted in an additional 30 to 45 minutes of wait out of the lot.\nIt was incredibly frustrating to have waited at the Apex line already, only to have cars that arrived hours after us hit the lanes ahead of us.\nApex can hold traffic and empty out the Will-Call line.\nWhy not do this?\n\n## TOC\n\nI worked a TOC shift on Sunday of Temple Burn.\nFor 6 hours, I had control of [this twitter account](https://twitter.com/bmantraffic) -- the first time I've ever posted anything on Twitter!\nThis was my chance to understand exodus, and to help tens of thousands of people to leave the Burn in the easiest way possible.\n\nI do not believe that, through any of my tweets, I helped anyone make better decisions.\nSome of my tweets were of the inane variety, like \"don't break down in the lanes\".\nI had a campmate whose car broke down on the way in, and he was just going to leave when it was time to leave -- the tweets had no bearing on his decision.\n\nThe most useful tweets could have been wait time estimates, and I believe that some of those were purely made up.\nI tweeted that the wait was [6 hours](https://twitter.com/bmantraffic/status/1566535630493913089), and tweeted again that the wait was [1 hour](https://twitter.com/bmantraffic/status/1566539015972474881) just 20 minutes later!\nThe amount of information coming to the TOC from folks on the ground is miniscule -- reporting wait times is not a huge priority, even though this is the one number everyone in the city wants to know.\nWe communicated this number to BMIR *maybe* twice during my six-hour shift, and once it was only because we had [totally stopped all traffic](https://twitter.com/bmantraffic/status/1566571695158153216) and asked them to report it.\nI didn't have a radio in my truck, but campmates reported that BMIR was more interested in their programming than in keeping folks informed about exodus -- just was well, since I don't believe they have any special information.\nAt least on Sunday afternoon, *nobody* seemed to have any accurate information about the wait time in Exodus.\n\nMy TOC shift lead was warm, personable, efficient on the radio, and a great person.\nHowever, I was sometimes shocked at their claims and decisions.\nAt the beginning of my shift, someone radioed into TOC, asking, \"BMIR is reporting a 3.5 hour wait time, do you know where they got that number\"?\nMy shift lead said, \"Yeah, that makes sense, because gate road is 4 miles long and the speed limit is 5 miles an hour.\"\nAfter some back-and-forth, the person on the radio signed off, unconvinced by this obviously faulty math, but clearly unwilling to continue taking up airtime.\nMy shift lead then told me to [tweet that number](https://twitter.com/bmantraffic/status/1566522222767812608)!\n\n## Exodus\n\nI left on Sunday night, shortly after my TOC shift ended.\nBecause I sent [this tweet](https://twitter.com/bmantraffic/status/1566539015972474881) about using all the lanes, I was able to satisfy my compulsion and skip a ton of traffic by using the empty lanes.\nThe pulses themselves, however, drove me nuts.\nSpecifically, in all my pulses, I observed the final portion of gate road completely draining of all cars -- nobody else merging onto the highway.\nExodus would then continue to hold traffic for anywhere from 20 to 40 minutes, for no reason I could discern.\nI sort of assumed this was because traffic was getting stuck on 447, but my brothers in black running Exodus that night assured me this was not happening.\n\nIt was sad to watch participants get into their vehicles and start them as they watched the road drain, then shut them down again 5 minutes later when the line showed no signs of movement.\nKeeping these people informed would help everyone.\n\n## Wrap-Up\n\nMy exodus took 9 hours (though it would've been 7 if my janky borrowed truck hadn't refused to start at the beginning of my last pulse!)\nTo everyone who helped out, including volunteers who brought me a jump box -- THANK YOU!)\nI know people who spent 11 hours in the full heat of Monday afternoon.\nThese anecdotes are, sadly, the best data we have!\nWhere are the charts of wait time by departure time over the years of exodus, the charts that would help level out traffic flows out of the city?\nIf your answer is \"leave Tuesday morning\", then you clearly don't understand the reality of participants who have to get back to their lives and jobs, but first must drive a theme camp home, unload it, and de-dust it.\n\nI can anticipate the reaction to this essay among the GPE crew.\nAt worst, I'll be dismissed as ignorant, not someone who trully understands the process and the constraints.\nGuity!\nTo these people, I would say that, if a 10-year department veteran is confused and frustrated by gate operations, then there's a real problem here.\nAt best, some GPE folks will tell me that, if I think I can do better, I should sign up -- as though there's a slot in the shift system for \"Run everything as you see fit\".\n\nMy goal is not to blindly criticize, but to contribute constructively.\nUltimately, I would love to just relax and enjoy the Gate process.\nI think a little bit of information would help me and the other participants to do just that.\n", "url": "https://igor.moomers.org/posts/open-letter-gpe", "title": "An Open Letter to GPE", "date_modified": "2022-09-09T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/peter-eckersley", "content_html": "\nI was at Burning Man 2022 when I heard that my dear friend [Peter](https://en.wikipedia.org/wiki/Peter_Eckersley_\\(computer_scientist\\)) was, initially, in critical condition.\nI learned later that evening that he had passed away.\nIn the midst of a difficult exodus full of logistics and dust storms, I kept finding myself with tears in my eyes, in a state of shock and disbelief that such a light in the world as Peter had gone out.\nI was grateful to learn the news while surrounded by friends and people who loved Peter.\nOur impromptu vigil at the Temple on Friday night was heartwarming and healing.\n\nI first met Peter back in 2009, and we ended up living together at the 1355 shortly after that year's Burn.\nIn the decade+ that I've known him, Peter has been much more than a friend.\nHe has been a collaborator, a mentor, and a source of inspiration.\nHe introduced me to good coffee.\nI have learned about the Bay area's best bike rides by riding them with Peter.\nHe showed me all the best dumpling restaurants.\nI learned about [giving what you can](https://www.givingwhatwecan.org/) from him, and made a commitment to donate a percentage of my income thanks to his example.\nPeter helped to bring me and my last long-term partner together -- a relationship that lasted 4 years.\nHe taught me about jasmine green pearls, and toast with a generous amount of butter.\nI cannot count the number of evenings we spent talking over the problems of the world, and how I would always learn something from him, shift my perspective just a little bit.\nHe taught me that it's possible to reason about the world.\n\nI last saw Peter about two weeks ago, when he came over to hang out while we prepared for Burning Man.\nInspired by one of our projects, he tried, as usual, to wrangle us into making another one on the spot.\nThat evening, in my dining room over Vietnamese food, I complained about the difficulty of fundraising for a climate startup I've been involved with.\nThough Peter has already introduced me to three potential investors over the last few months, he said to me, \"I will work harder for you.\"\nThis may be one of the last things he said to me, and perfectly sums up his generosity and his unwavering enthusiasm.\n\nAs I reflect on my relationship with Peter, I can't help but feel that I took his presence for granted.\nHe was just such a pillar, a constant of the world, always available for dinner or a chat.\nI don't think I've ever told him just how much I appreciated him.\nHis passing is a reminder to me, to take every chance I get to share my appreciation with the people in my life.\n\nPeter's passing also leaves a hole in the world.\nWho is going to make sure AI is on our side?\nWho will take a stand for privacy and security?\nWho will bring people together to solve seemly-intractable problems?\nWhere will all the quirky ideas come from?\n\nI think the best way that I can honor Peter's memory is to take on some of the work he has left behind.\nI want to throw one extra dinner party.\nI want to go on one more extravagant bike ride, which is nothing more than an excuse to stop for coffee and banana bread.\nMost of all, I want to remain engaged and enthusiastic in the world.\nIf I've learned anything from Peter, it's that any problem is solvable though reason and cooperation.\n\nPeter, I will miss you always.\n", "url": "https://igor.moomers.org/posts/peter-eckersley", "title": "Peter Eckersley", "date_modified": "2022-09-08T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/war-in-ukraine", "content_html": "\nI was born in [Mykolaiv, Ukrain](https://en.wikipedia.org/wiki/Mykolaiv).\nI lived there until age 9, when my family emigrated to Los Angeles.\nOver the years, much of my immediate family has likewise emigrated to the US.\nHowever, I still have many extended family members there.\n\nI haven't been back to Ukraine since I left as a child.\nMy parents, however, have returned several times to visit friends and family.\nI feel strong personal connections both to the city itself, and to the well-being of my many family members living there.\nWatching the [Battle of Mikolaiv](https://en.wikipedia.org/wiki/Battle_of_Mykolaiv) take place, both through media and through family updates, has therefore been stressful, distracting, and unsettling.\n\n## Family Update ##\n\nAs of today, I have three separate groups of family members who've been affected by the war in Mykolaiv.\nMy closest relative, an uncle, was living in the city but is an Autralian citizen.\nAround February 25th, he took himself and much of his Ukranian family to Poland.\nWe had confirmation that he arrived in Warsaw on March 4th.\n\nMore family members have fled to western Ukraine.\nAdult males are currently prohibited from leaving Ukraine, so the family is staying in the country to stay together.\nAnother big group has a house with a basement, which they've been using as a bomb shelter.\nThey've been descending there whenever the air raid sirens go off.\n\n## Predictions ##\n\nI planned a family gathering for the past weekend, and naturally, Ukraine was all we could talk about.\nAfter much kitchen-table debate where people were making informal/implicit predictions, I tried to make things more concrete by formalizing them and writing them down.\nSince so many folks have been asking me what I think about this conflict, I figured I would share my predictions publicly.\n\n### The End of the Conflict ###\n\nA common question I get is about the end-game of the war.\nI think Russia will, eventually, seize Kiev and install a puppet regime.\nThis regime will be highly unpopular, but it will remain in power through Russian military and intelligence support.\nThe closest analogs for this, for me, are Syria and Belorus -- both places where an unpopular leader has resisted all attempts at regime change.\nIn Syria in particular, the cost was the destruction of a large part of civilian infrastructure.\nUkraine is already there after two weeks of bombing, and will continue to get worse.\n\n[This article](https://carnegieendowment.org/2022/03/03/how-does-this-end-pub-86570) confirmed my existing biases about the end-game.\nI agree that the task, for the west, is to avoid escalation at all costs, even though the outcome for Ukrainians seems pretty dire.\nThe alternative -- a possible nuclear confrontation -- is worse, for everyone.\n\n### Putin and His Circle ###\n\nMany of my family members were convinced that this is the end game for Putin personally.\nI disagree.\nPutin is powerful, paranoid, and ruthless.\nIf he's able to prop up extremely unpopular dictators in other countries, he'll definitely be able to do it at home.\nI predict that he will remain in power until he dies, and his death will likely be of natural causes.\n\nMy family members were wondering about the oligarchs, who are having assets seized and being sanctioned by foreign governments.\nWhat's the point of being a billionaire if you can't jet around the world on your private plane to your private yacht?\nThere was a \"surely, they'll kick him out now that he no longer benefits them\" thread.\nAgain, I disagree.\nThe oligarchs serve at Putin's mercy, as he showed with [Khodorovsky](https://en.wikipedia.org/wiki/Mikhail_Khodorkovsky).\nI also recommend the book [Nothing Is True and Everything Is Possible](https://bookshop.org/books/nothing-is-true-and-everything-is-possible-the-surreal-heart-of-the-new-russia/9781610396004) for an in-depth look at how Putin plays his allies against each other, all the while securing even more power for himself.\n\n### Energy/Climate ###\n\nRussia can balance it's budget with an oil price of [$45 per barrel](https://www.bloomberg.com/news/articles/2019-08-22/putin-s-budget-has-lowest-break-even-oil-price-in-over-a-decade) (paywall).\nThe price is north of $100 at the moment.\n\nThere are serious people in the EU who are thinking about [a future without Russian gas](https://www.bruegel.org/2022/02/preparing-for-the-first-winter-without-russian-gas/).\nGiven the politics in the West, this might actually happen, but the impact to Russia will be minimal.\n\n> crude oil accounted for $110.2 billion, oil products for $68.7 billion, pipeline natural gas for $54.2 billion and liquefied natural gas $7.6 billion\n\n([source](https://www.reuters.com/markets/europe/russias-oil-gas-revenue-windfall-2022-01-21/)).\nSo, even if we assume all pipelines stop flowing, Russia will still find a ready export market for the remaining 80% of it's fossil fuels.\nWhile the conflict might accelerate renewables transition in the EU, it also has a bunch of negative knock-on effects.\nMost especially, it makes burning coal a better deal -- something [the EU is already struggling with](https://www.newyorker.com/magazine/2022/02/07/can-germany-show-us-how-to-leave-coal-behind).\nIn addition, fracking becomes more profitable again, as does refining poor-quality petroleum such as tar sands.\n\nThe US administration was already walking a fine line between advocating a renewables shift while also protecting low gas prices at all costs.\nThe calculus there has become harder, and the administration will face tough choices.\nApprove more drilling and face the anger of the base?\nDeny new oil and gas leases, and face the political consequences?\n\n## Political Opportunity ##\n\nThis war is very prominent in public conciousness, and people want a frame in which to think about it.\nI recommend using the following frame whenever talking to anyone about this conflict.\n\n__This War Is a Climate War__.\nPutin is just one more character in the cast of fossil-fuel-powered dictators.\nHe's been wreaking havoc on the world stage for 20 years, and the world rolled over and took it because he supplied the gas.\nEvery bullet shot at a Ukrainian citizen, every missile hitting a residential building, every tank and warplane was paid for when Westerners pumped their gas and turned up their heat.\n\n__Ukrainian refugees are climate refugees__.\nThey were displaced because of fossil fuels.\nThey join migrants from the Syrian civil war, and the people coming to the US from South and Central America -- all people displaced by our addiction to fossil fuels.\n\n__The climate crisis is a refugee crisis__.\nMillions of Ukrainians fleeing to the EU is a foreshadowing of what's to come.\nWe are reacting today in the best possible climate -- a very unpopular war, a very definite and very unpopular aggressor, very sympathetic (because white, Christian) victims.\nHow we treat these folks is the best-case scenario, and it [could be better](https://www.reuters.com/world/europe/britain-may-ease-immigration-rules-ukrainian-refugees-sun-2022-03-07/?taid=62260ffc18c5730001d4f729).\n", "url": "https://igor.moomers.org/posts/war-in-ukraine", "title": "The War in Ukraine", "date_modified": "2022-03-07T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/words-i-avoid", "content_html": "\nLanguage shapes thought -- a.k.a, [the Sapir-Whorf hypothesis](https://www.sciencedirect.com/topics/psychology/sapir-whorf-hypothesis).\nThere's lots of good evidence for this -- for instance, a very popular study on how Russian's multiple words for shades of blue allow speakers to [more rapidly distinguish between those shades](https://www.newscientist.com/article/dn11759-russian-speakers-get-the-blues/).\n\nDifferences in thought patterns might arise not just between speakers of different languages, but between individuals speaking the same language.\nI'm specifically interested, here, in [cognitive distortions](https://www.theschoolofmomentum.com/post/cognitive-distortions), -- a kind of dialect spoken by people who are clustered together, not through physical geography but on a memetic landscape.\nCognitive distortions [are correlated with depression](https://www.nature.com/articles/s41562-021-01050-7).\nThere are even claims that [we might be getting more depressed as a society, based on increasing prevalance of cognitive distortions in public text](https://www.pnas.org/content/118/30/e2102061118).\n\nThis is interesting, but is a post-hoc justification for a practice that I noticed myself independently adopting.\nLanguage forces a frame of thought, sometimes those frames are not helpful, and language can be a clue that a specific frame is arising.\nWhen I notice myself using these words, this is a clue to myself to pay attention and possibly to re-frame my thinking.\nWithout further ado, my listsicle.\n\n## SHOULD ##\n\nThis is the most common one I notice in myself, and in many of the people in my life.\nOften used like \"I *should* stop being on the computer so much\" or \"I *should* exercise more\".\nAn old housemate used to react to *should*s by saying, \"Don't *should* all over yourself\".\n\nI dislike the way *should* imposes an obligation.\nIt's not that I *should* go brush my teeth -- it's that I *want* to have healthy teeth and good breath.\nReminding myself of my motivations is often helpful in getting myself to actually do the task.\n\nI also don't like imposing *should*s on others.\nInstead of saying \"You *should* read X\", I could say \"I think you would like X\".\nWhile reframing in this way, I sometimes realize that I'm not even sure the person would even enjoy X -- I end up simply telling a story, like \"I enjoyed X, because...\" -- allowing me to share excitement and enthusiasm without adding a TODO to my interlocutor's list.\n\n## MAKE[s] [ME/YOU] FEEL ##\n\nI suffer from the influence of what a wise person I know once called \"the control virus\" -- the mistaken desire, and belief in the ability to, control outcomes in the world.\nFor instance, I cannot control the world's climate, or the way the world responds to climate change.\nWhat I can control is how I engage with that problem, how I show up in relationship to it.\nDo I avoid thinking about it?\nDo I let it dominate my life and take away my joy?\n\nA global catastrophe is a more obvious example.\nBut the control virus shows up more frequently in interpersonal interactions.\nI can't control whether or not my housemate washes their dishes, for instance.\nThis is insidious because it seems like, if I just ask them \"correctly\" -- if I say just the right words that would inspire just the right feelings of solidarity and guilt -- then maybe the dishes will get washed after all.\nIn other words, I would get the outcome that I wanted.\n\nThinking about life in terms of desired outcomes is a recipe for dissatisfaction.\nThere is gratitude when my housemate chooses to wash their dishes, while if I somehow controlled their actions via the right words, all I get is smug self-satisfaction.\nAnd what of the alternate scenario?\nIf they didn't wash their dishes after our conversation, I can be mad at myself for not saying those magic correct words, and mad at the housemate for depriving me of my desired outcome.\n\nI find it helpful, through life, to remind myself that I am fundamentally not in control of outcomes.\nAll that I can choose -- and even that, with great difficulty -- is how I feel in a given moment.\nI can feel drained, avoidant, anxious, and withdrawn from the problem of climate change -- or I can be motivated to engage through feelings of love, the joy of building and creation.\nI can be frustrated at my housemate, or I can be curious and supportive of the challenges in their life, and inspired to build a more harmonious household (including by being less frustrated in general).\n\nI think the freedom to choose my own feelings in the moment is the greatest possible freedom.\nIt often seems non-existent -- always, the temptation to react in a way that I might later regret, not in alignment with the kind of person I would like to cultivate.\nSo, it is difficult enough to obtain this freedom without constantly, voluntarily surrendering it to others.\n\nThis is why *makes me feel* is such a agency-robbing expression.\nMy usual retort to this, inside my own head, is \"nobody can *make* you feel anything!\"\nPeople who up in the way that they choose, and then I feel about it the way that I feel.\nSometimes, my reframing of this phrase takes an [NVC](https://www.cnvc.org/learn-nvc/what-is-nvc) turn -- \"when you leave your dishes unwashed, I feel...\".\nWhen talking of others, I can pivot \"I'm sorry I made you feel X\" into an opportunity to think about exactly what I said or did that proved a reaction.\nFor instance, seeing that a person is angry, I can take a moment to think about what I said which provoked anger.\nSaying \"I'm sorry I said X\", instead of \"I'm sorry I made you angry\" acknowledges the person's feelings and my role in them, while leaving intact their agency in the situation.\n\n## JUST ##\n\nI got this from one of my housemates, who pointed out that the word *just* is often doing a lot of heavy lifting in a sentence.\nHaving trouble with your boss/spouse/child/pet/inanimate object?\nWhy not *just* ...?\nThis can often be quite patronizing.\nThere's an impression that the solution to a problem is trivial, deadening curiosity through a mistaken belief that you already know the right answer.\n\nThere's no catch-all reframing for *just*, but many paths depending on the conversation and relationship.\nIs your manager being a jerk in meetings?\nA common script devolves into naive solution-ism -- \"You could *just* complain to **their** manager!\"\nWhen you notice that *just*, that's the cue.\nOne option is sympathy -- \"Damn, that sounds terrible, I would be so mad in your situation.\"\nAnother option is collaborative problem solving, but with curiosity -- \"Does **their** manager know about this behavior? How would she react if she knew?\"\n\n## Putting it all together ##\n\nAn Igor of a few years ago might say something like \"My manager makes me feel so angry in meetings! I should just go complain to the VP.\"\nA hopefully-more-self-aware Igor of today might notice several opportunities for deeper reflection here.\nWhy am I feeling angry about the situation?\nHow can I work, both internally and externally, towards a different reaction in that situation?\nDo I want to bring external parties to help mediate the conflict?\nWould that help the situation, or escalate it?\n\nThe goal is not inactive analysis paralysis.\nInstead, I want to give myself the chance to avoid reacting to situations, because my reactions often have the opposite effect from the one I desire.\nIf I avoid reacting and create spaciousness even in difficult situations, I can use the spaciousness to choose a path most likely to help me feel best in the future.\n", "url": "https://igor.moomers.org/posts/words-i-avoid", "title": "Words I Avoid", "date_modified": "2021-09-24T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/kitchen-table-decisions", "content_html": "\nI've been spending a bunch of time, both personally, and professionally, thinking about the clean energy transition and \"kitchen table decisions\".\nSome examples of kitchen-table decisions:\n\n* where to live\n* how to heat the home/heat water for home use\n* whether to get solar panels\n* whether to use an electric car\n* whether to get battery storage\n* how to insulate the home\n* how to do laundry and drying\n* how to cook food in the home\n* what kind of food to eat\n* what kinds of vacations to take\n* how and when to shop for consumer goods\n\nThese are in (very rough) order of importance in terms of climate impact.\nMy professonal thoughts on this have mostly come from my involvement in the [Rewiring America](https://www.rewiringamerica.org/) project.\nI've been working on data mining and analysis to quantify the impact of some of these decisions.\nFor instance, I helped put together [a map](https://map.rewiringamerica.org/) which shows which households would most benefit from switching to [heat pump](https://www.carrier.com/residential/en/us/products/heat-pumps/what-is-a-heat-pump-how-does-it-work/)-based heating, and also to quantify the [CO2e](https://coolerfuture.com/en/blog/co2e) savings from such a transition.\n\nPersonally, I am thinking of these projects as a co-owner at [Chrysalis](https://chrysalis.community/).\nBecause we are co-housing, we get a multiplier effect from many of these decisions.\nFor instance, getting a single heat pump space or water heater for our one household is the equivalent of as many as three or four \"normal\" nuclear-family households.\nOur group is pretty committed to making long-term investments that benefit the environment, and we're in the process of making decisions on many of them.\n\nAs we do the research and make big investments, I would also like to document what we are learning.\nI'm envisioning this post being the entry-point for more in-depth discussions.\nPlease get in touch if you have valuable experiences to share, or would like to know more about some of these subjects.\n", "url": "https://igor.moomers.org/posts/kitchen-table-decisions", "title": "Kitchen Table Decisions", "date_modified": "2021-08-09T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/navigating-arch-on-osx", "content_html": "\nI started a new job, and this job came with a new computer -- an Apple M1 MacBook.\nI had to do quite a bit of work to get my usual dev environment set up, mostly having to do with the transition to the `amd64` architecture from `x86_64`.\nSome tips and tricks are documented here.\n\n## Two `homebrew`s\n\nI found [this stack overflow question](https://stackoverflow.com/a/64951025/153995) invaluable.\nOn my computer, I had already run the normal homebrew install command:\n\n```bash\n/bin/bash -c \"$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)\"\n```\n\nThis installed homebrow into `/opt/homebrew`.\nTo also add an x86_64 version of homebrew, I did:\n\n```bash\ncd /usr/local\nsudo mkdir homebrew\nsudo chown :staff homebrew\nsudo chmod g+w homebrew\ncurl -L https://github.com/Homebrew/brew/tarball/master | tar xz --strip 1 -C homebrew\n```\n\nI then followed the stack overflow question, and added an alias to my `.bash_profile`:\n\n```bash\nalias brow='arch --x86_64 /usr/local/homebrew/bin/brew'\n```\n\n## Python with `asdf` / `pyenv`\n\nApparently, Python newer than 3.9.1 [natively supports arm64](https://github.com/pyenv/pyenv/issues/1768).\nAlas, I needed Python 3.8.9, which is what my co-workers use:\n\n```bash\n$ asdf install python 3.8.9\npython-build 3.8.9 /Users/igor47/.asdf/installs/python/3.8.9\npython-build: use openssl@1.1 from homebrew\npython-build: use readline from homebrew\n\n<-- snip -->\n\nBUILD FAILED (OS X 11.2.3 using python-build 1.2.27-29-gfd3c891d)\n\n<-- snip -->\n\nconfigure: error: Unexpected output of 'arch' on OSX\n```\n\nThis still does not work if you explicitly specify an arch:\n\n```bash\n$ arch -x86_64 asdf install python 3.8.9\npython-build 3.8.9 /Users/igor47/.asdf/installs/python/3.8.9\npython-build: use openssl@1.1 from homebrew\npython-build: use readline from homebrew\n\n<-- snip -->\n\nInstalling Python-3.8.9...\npython-build: use readline from homebrew\npython-build: use zlib from xcode sdk\nWARNING: The Python readline extension was not compiled. Missing the GNU readline lib?\nERROR: The Python ssl extension was not compiled. Missing the OpenSSL lib?\n\nBUILD FAILED (OS X 11.2.3 using python-build 1.2.27-29-gfd3c891d)\n```\n\nYou'll need to install the `x86_64` versions of readline and openssl to make progress!\nThe second install of brew to the rescue (notice, I'm using my alias, `brow` and not `brew`, below):\n\n```\n$ brow install readline\n$ brow install openssl\n$ brow install xz\n```\n\nNow, you need those libraries in your linker and compiler.\nI figured I might need to do this again, so I am using my [direnv](https://github.com/asdf-community/asdf-direnv) setup to make this easier.\nI created a directory -- `mkdir ~/x86_64` -- and added a `.envrc` that looks like this:\n\n```bash\nuse asdf\nexport BROW=\"/usr/local/homebrew\"\nexport LDFLAGS=\"-L${BROW}/opt/openssl@1.1/lib -L${BROW}/opt/readline/lib -L${BROW}/opt/xz/lib\"\nexport CPPFLAGS=\"-I${BROW}/opt/openssl@1.1/include -I${BROW}/opt/readline/include -I${BROW}/opt/xz/include\"\nexport PATH=\"${BROW}/bin:$PATH\"\nexport ARCHPREFERENCE=\"x86_64\"\n```\n\nA quick `direnv allow`, and now, when I `cd ~/x86_64`, I am in a good place to do Rosetta-type things:\n\n```bash\n$ uname -a\nDarwin planetarium.local 20.3.0 Darwin Kernel Version 20.3.0: Thu Jan 21 00:06:51 PST 2021; root:xnu-7195.81.3~1/RELEASE_ARM64_T8101 arm64\n$ cd ~/x86_64\ndirenv: loading ~/x86_64/.envrc\ndirenv: using asdf\ndirenv: loading ~/.asdf/installs/direnv/2.28.0/env/3601927912-4079855243-2014015008-304321844\ndirenv: using asdf rust 1.52.1\ndirenv: using asdf python 3.8.9\ndirenv: using asdf direnv 2.28.0\ndirenv: export +ARCHPREFERENCE +CARGO_HOME +CPPFLAGS +LDFLAGS +RUSTUP_HOME ~PATH\n$ arch uname -a\nDarwin planetarium.local 20.3.0 Darwin Kernel Version 20.3.0: Thu Jan 21 00:06:51 PST 2021; root:xnu-7195.81.3~1/RELEASE_ARM64_T8101 x86_64\n```\n\nNow, from this directory, I can easily install my Python.\nI didn't have to specify `-x86_64` to `arch`, because this is already set by my `ARCHPREFERENCE`.\n\n```bash\n$ arch asdf install python 3.8.9\n<-- snip -->\nInstalled Python-3.8.9 to /Users/igor47/.asdf/installs/python/3.8.9\n```\n", "url": "https://igor.moomers.org/posts/navigating-arch-on-osx", "title": "x86_64 on an Apple M1 MacBook", "date_modified": "2021-05-11T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/arch-linux-config", "content_html": "\nAfter encountering some issues with Ubuntu on my Thinkpad X1 Carbon 6th-gen, I went back to Arch linux.\nSo far, I'm loving it, but I did have to figure out a few things.\nThis is meant to document a few things I did to customize the machine to my liking.\n\n## Re-mapping CapsLock to Ctrl \n\nMy brain is very used to the caps lock key being the control key.\nWhen this is not remapped, I end up constantly switching into all-caps mode and being very confused when things don't work correctly.\nI used [interception](https://gitlab.com/interception/linux/tools) and the [caps2esc](https://gitlab.com/interception/linux/plugins/caps2esc) plugin to make the re-mapping work in a virtual console as well as in X.\n\nFirst, install `caps2esc` (I use the [yay](https://github.com/Jguer/yay#installation) package manager):\nI picked the `community/interception-caps2esc` package, which was option `1` in the `yay` listing.\n\n```bash\n$ yay caps2esc\n```\n\nNext, configure the re-mapping.\nI use `-m 1` to disable the mode where pressing `esc` turns on caps lock, since I like the escape key to just remain the escape key and don't really need caps lock.\nThis configuration goes into the file `/etc/interception/udevmon.yaml`:\n\n```yaml\n- JOB: intercept -g $DEVNODE | caps2esc -m 1 | uinput -d $DEVNODE\n DEVICE:\n EVENTS:\n EV_KEY: [KEY_CAPSLOCK]\n```\n\nFinally, enable and activate the `udevmon` service, and enjoy no-more caps lock:\n\n```bash\n$ sudo systemctl enable udevmon\n$ sudo systemctl start udevmon\n```\n\n## Auto-suspend on low battery\n\nOccasionally, I leave my laptop with the lid open for a reason.\nOther times, I just forget about it.\nI always feel bad coming back to a dead computer with a battery at 0%, since this can [reduce the lifetime of the battery](https://electronics.stackexchange.com/questions/164103/if-li-ion-battery-is-deeply-discharged-is-it-harmful-for-it-to-remain-in-this-s).\n\nTo prevent this, I have a script which will auto-suspend my computer if the battery level drops too low.\nI use this script (which I put into my `~/bin/auto_suspend.sh` and made executable with a `chmod u+x`):\n\n```bash\n#!/bin/bash\n\nbattery_level=`cat /sys/class/power_supply/BAT0/capacity`\n\nif [ \"$battery_level\" -le 5 ]\nthen\n notify-send \"Battery critical. Battery level is ${battery_level}%! Suspending...\"\n sleep 5\n systemctl suspend\nelif [ \"$battery_level\" -le 8 ]\nthen\n notify-send \"Battery low. Battery level is ${battery_level}%!\"\nfi\n```\n\nTo run this script periodically, I used [systemd timers](https://wiki.archlinux.org/index.php/Systemd/Timers) (since Arch does not come with a cron daemon installed in the base system).\nFirst, I created a unit file for my auto-suspend service, in `~/.config/systemd/user/auto_suspend.service`:\n\n```\n[Unit]\nDescription=Checks battery and suspends if low\n\n[Service]\nType=oneshot\nExecStart=/home/igor47/bin/auto_suspend.sh\n```\n\nNext, I created a timer which will periodically activate this service (in `~/.config/systemd/user/auto_suspend.timer`):\n\n```\n[Unit]\nDescription=Check battery level and auto-suspend\n\n[Timer]\nOnBootSec=1m\nOnUnitActiveSec=1m\n\n[Install]\nWantedBy=timers.target\n```\n\nMy config will activate the timer 1 minute after boot-up, and also 1 minute after every activation.\nI then enable the timer:\n\n```bash\n$ systemctl --user daemon-reload\n$ systemctl --user enable auto_suspend.timer\n$ systemctl --user start auto_suspend.timer\n```\n\nYou can check the status of the timer like so:\n\n```bash\n$ systemctl --user list-timers\n```\n", "url": "https://igor.moomers.org/posts/arch-linux-config", "title": "Arch Linux Configuration", "date_modified": "2021-01-27T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/minimal-viable-air-quality", "content_html": "\nIf you, like me, live in the Bay Area, you may have woken up to something like this last week:\n\n\n\nThis is my back yard, but things looked just as dire in the house:\n\n\n\nIf you checked a website, like [PurpleAir](https://www.purpleair.com/map?opt=1/mAQI/a10/cC0#8/38.138/-121.702) or [AirNow](https://fire.airnow.gov/?lat=37.86988000000008&lng=-122.27053999999998&zoom=12), you would see scary numbers and dire warnings about staying indoors and avoiding the air outside.\nHowever, how *is* the air inside your house?\nAre you actually much safer?\n\nThankfully, answering this question has gotten cheaper and easier in recent years.\nLow-cost air quality sensors have been built into reasonably inexpensive hardware.\nThe [PurpleAir indoor sensor](https://www2.purpleair.com/products/purpleair-pa-i-indoor), for instance, is only $200.\n\nThe heart of that device is a plantower laser dust sensor which can be [had on AliExpress for about $12](https://www.aliexpress.com/item/32639894148.html).\nWith PurpleAir, you're paying for more than just the sensor.\nThat device includes a [BME280](https://learn.adafruit.com/adafruit-bme280-humidity-barometric-pressure-temperature-sensor-breakout) temperature/pressure/humidity sensor, a microcontroller that can access a WiFi network, GPS that helps localize the device on a map, all conveniently packed into a nice-looking device.\nYou pay for integration of all that hardware, firmware to make it work together, and software that integrates the data on the back-end and gives you a nice map to view it on.\nYou're also paying for hosting to allow PurpleAir to store your data and display it to others.\nSo, by buying one, you're not only becoming better-informed, but you're also helping folks in your neighborhood be better-informed too -- a *positive* externality, for once!\n\nHowever, if you're brave enough, there are advantages to building the hardware yourself.\nGetting several sensors inside and outside your house can help you understand more about the air you're breathing.\nIt can help quantify interventions, like installing an air purifier or running [a box fan](https://www.texairfilters.com/how-a-merv-13-air-filter-and-a-box-fan-can-help-fight-covid-19/).\nIf you have a large house, you can see how quality differs throughout the house.\n\nAlso -- while for most readers of this blog, $200 is probably not a lot of money, it *is* a lot of money for *most* people.\nThe folks who are most regularly affected by poor air quality are exactly those who cannot just blow $200 to satisfy their curiosity.\nMaking air quality monitoring much, much cheaper can potentially make life much better for those people.\n\nThis post will help you build a minimum viable sensor that works with your laptop.\nBy using a pre-existing computer, you can avoid having to pay for additional hardware like a microcontroller with WiFi.\nYour computer is probably already on WiFi, so configuration is also minimized.\n\nYou can also avoid sending data to a cloud.\nThis is a double-edged sword.\nOn the one hand, cloud hosting costs are eliminated.\nOn the other hand, you lose the positive benefits of open data.\nAlso, if you want visualizations, you have to make them yourself.\n\nAnyway, on to the construction!\n\n## Hardware \n\nThe bill of materials for this project includes two things:\n* Plantower PMS7003 -- maybe [this one](https://www.aliexpress.com/item/32784279004.html)\n* A USB-to-TTL cable like [this one](https://amzn.to/2GYAYAD)\n\nThis should run you about $20 all-told.\nI also needed the following tools and supplies:\n* soldering iron and solder\n* heat shrink tubing and a lighter\n* wire clippers/strippers\n\nThe PMS7003 sensors I had did not come with the little breakout board, and this device has *very* small pins.\nTo connect to it, I used some 30AWG wire-wrap wire and a wire-wrapping tool.\nIf you get a PMS7003 with a breakout and cable, you won't need this.\n\nMy first task was connecting to the PMS7003.\nHere's the pinout, from the [data sheet](https://download.kamami.com/p564008-p564008-PMS7003%20series%20data%20manua_English_V2.5.pdf):\n\n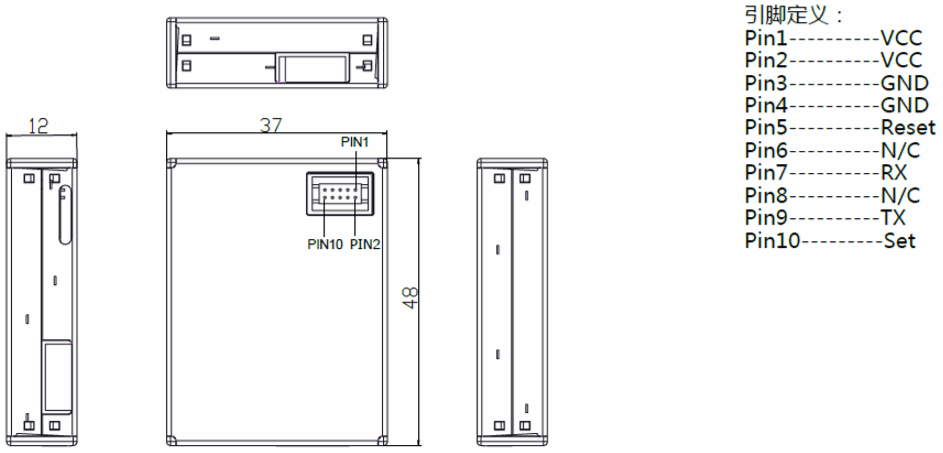\n\nYou'll only need 4 wires -- for power, ground, serial Tx, and Rx.\nI stripped the tiniest bit of insulation on my wire wrap wire, tinned both the wire and the pin, and touched them together with the soldering iron (very carefully, to avoid bridging the pins).\n\n\n\nHere's a (blurry) photo with all 4 wires connected:\n\n\n\nNext, I stripped my USB TTL cable and tinned the exposed multi-strand wires.\nTinning just means touching the soldering iron to the wire and allowing some solder to flow onto the wire.\nThis makes the wire stiff, so I can wire-wrap onto it using my wire-wrap tool.\n\n\n\nNext, I wire-wrapped the exposed, tinned wires.\nBlack and Red are for ground and power, and get connected together.\nOn my TTL cables, `green` is for `Tx` (transmit) and `white` is for `Rx` (receive).\nYou need to connect the `Tx` of the PMS7003 to the `Rx` of the TTL cable, and vice versa.\nI made it easier for myself by making my `white` wire on the PMS7003 be the `Tx` pin (Pin9), so I could just do white-to-white:\n\n\n\nAfter wire-wrapping, I soldered the wires together (belt *and* suspenders!)\nFinally, I put some heat-shrink tubing over the wires and shrunk it using a lighter.\nI then taped the device right to the USB plug with electrical tape.\nBe sure to avoid covering up the air intake and expel ports on the PMS7003.\nAlso, be mindful of USB polarity.\nThe orientation that I have in the photo is probably the way your USB port is aligned on your computer, so the PMS7003 ends up on top of the USB plug.\n\n\n\nHere it is, plugged into my computer and ready for software integration:\n\n\n\n## Software\n\nNext, you'll need some software to integrate with this hardware.\nThe cables that I got use the Prolific Technology PL2303 chipset.\nThis is already supported on linux; if you plug it in and run `dmesg | tail` you'll see something like this:\n\n```\n[1457958.125315] usb 1-2: new full-speed USB device number 38 using xhci_hcd\n[1457958.281810] usb 1-2: New USB device found, idVendor=067b, idProduct=2303, bcdDevice= 4.00\n[1457958.281816] usb 1-2: New USB device strings: Mfr=1, Product=2, SerialNumber=0\n[1457958.281820] usb 1-2: Product: USB-Serial Controller\n[1457958.281823] usb 1-2: Manufacturer: Prolific Technology Inc.\n[1457958.283810] pl2303 1-2:1.0: pl2303 converter detected\n[1457958.285306] usb 1-2: pl2303 converter now attached to ttyUSB0\n```\n\nLooks like it got recognized correctly, and is available at `/dev/ttyUSB0`.\nOn OSX, you will probably have to [install a driver](http://www.prolific.com.tw/US/ShowProduct.aspx?p_id=229&pcid=41), but you can ignore the warning about restarting your computer.\nOn these machines, the device will probably show up at `/dev/tty.usbserial`.\n\nWhile it has power, the PMS7003 will be outputting a continuous stream of binary data containing the particulate readings onto that TTY device.\nThe [data sheet](https://download.kamami.com/p564008-p564008-PMS7003%20series%20data%20manua_English_V2.5.pdf) specifies the protocol:\n\n\n\nI recommend using my [mini-aqi repo](https://github.com/igor47/mini-aqm), which includes a Python implementation of this protocol.\nYou will need a recent python (I tested with `3.8.3`; anything above `3.6` should probably work).\nRun these commands to grab the repo, install the code, and begin reading data:\n\n```bash\ngit clone https://github.com/igor47/mini-aqm.git\ncd mini-aqm/\npip install poetry\npoetry install\npoetry run ./main.py\n```\n\nAnd you should see the output:\n\n```\nbeginning to read data from /dev/ttyUSB0...\nPM 1.0: 32 PM 2.5: 54 PM 10: 73 AQI: Unhealthy for Certain Groups\nPM 1.0: 31 PM 2.5: 54 PM 10: 73 AQI: Unhealthy for Certain Groups\n```\n\nHere's a screenshot:\n\n\n\n`mini-aqm` tries to print informative error messages.\nIf `main.py` exits immediately without printing any air quality measurements, read the error message and try to resolve it.\nIf you suspect a hardware issue, use a multi-meter to check for a short between pins.\n\n## Visualizations\n\nI am running [telegraf](https://www.influxdata.com/time-series-platform/telegraf/) on my laptop.\nI've configured telegraf to read data from the device and store it in [influxdb](https://www.influxdata.com/products/influxdb-overview/), for graphing with [grafana](https://grafana.com/).\nUsing this stack, here's a visualization of the past few months of PM data in my workshop:\n\n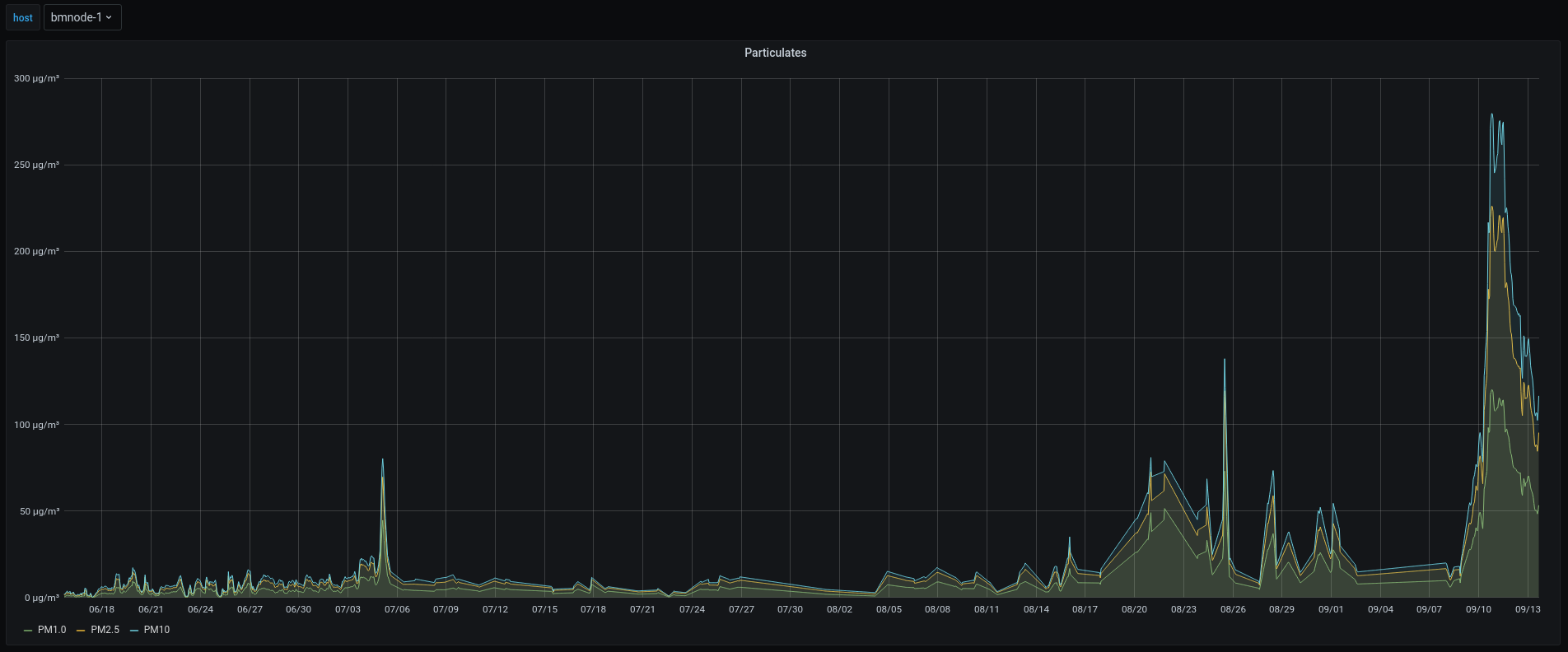\n\nUsing this setup, it's convenient to perform experiments and look at results.\nFor instance, here is what happened with indoor air quality when we turned on our central fan system, which pushes air through two MERV13 filters:\n\n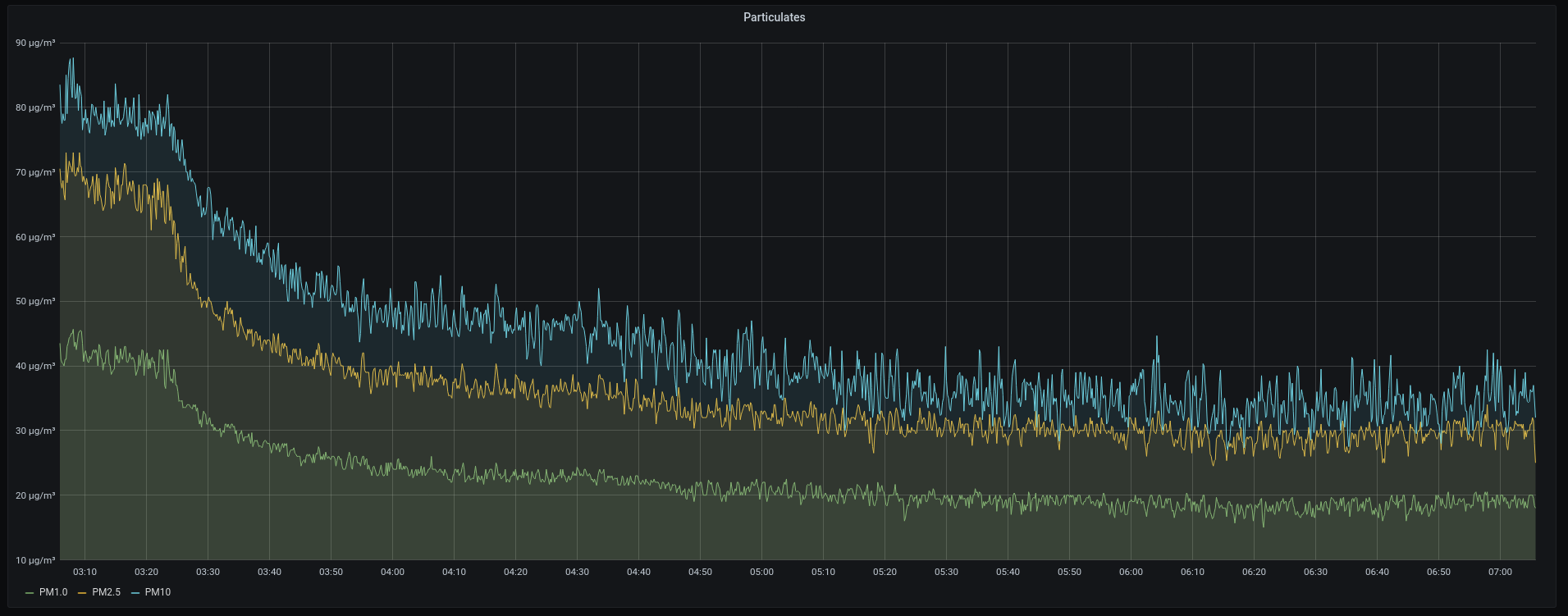\n\nHere's where we take a box fan with a MERV13 filter and run it near the sensor:\n\n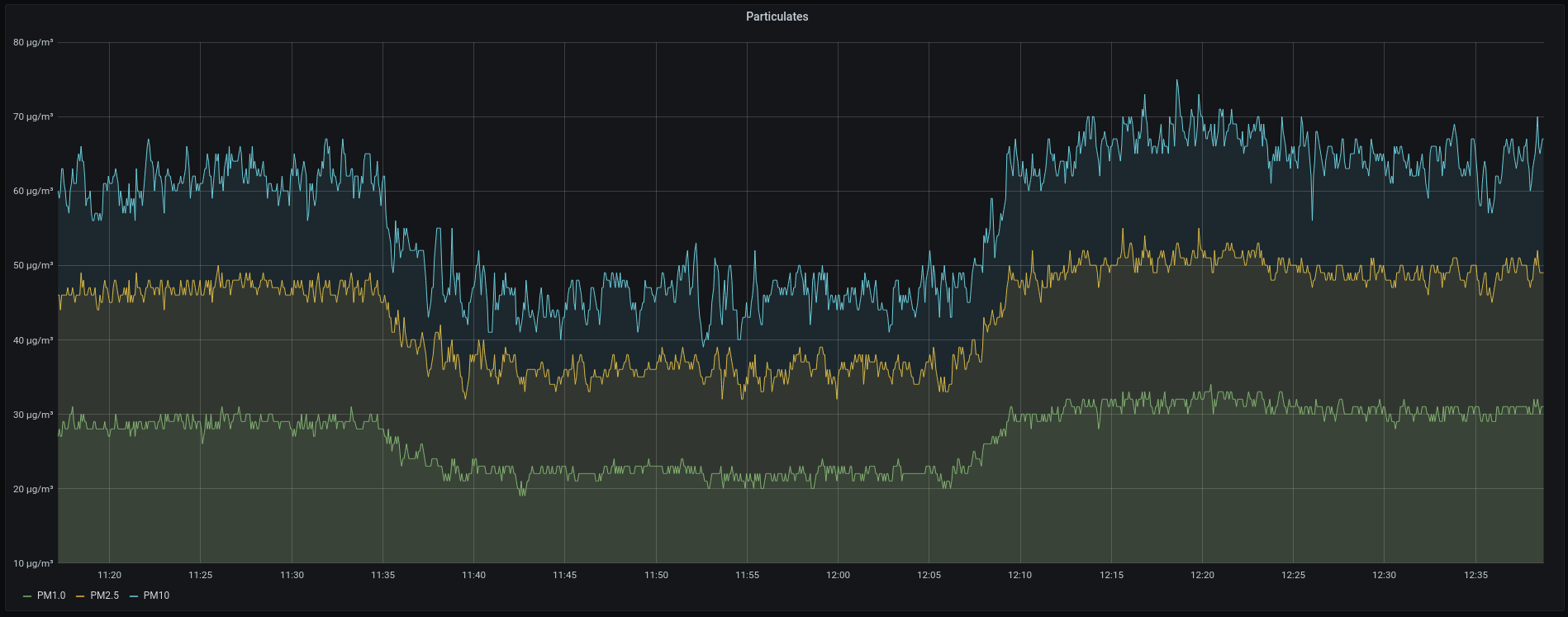\n\nHere's what happens when we just point a normal fan at the device, with no filter:\n\n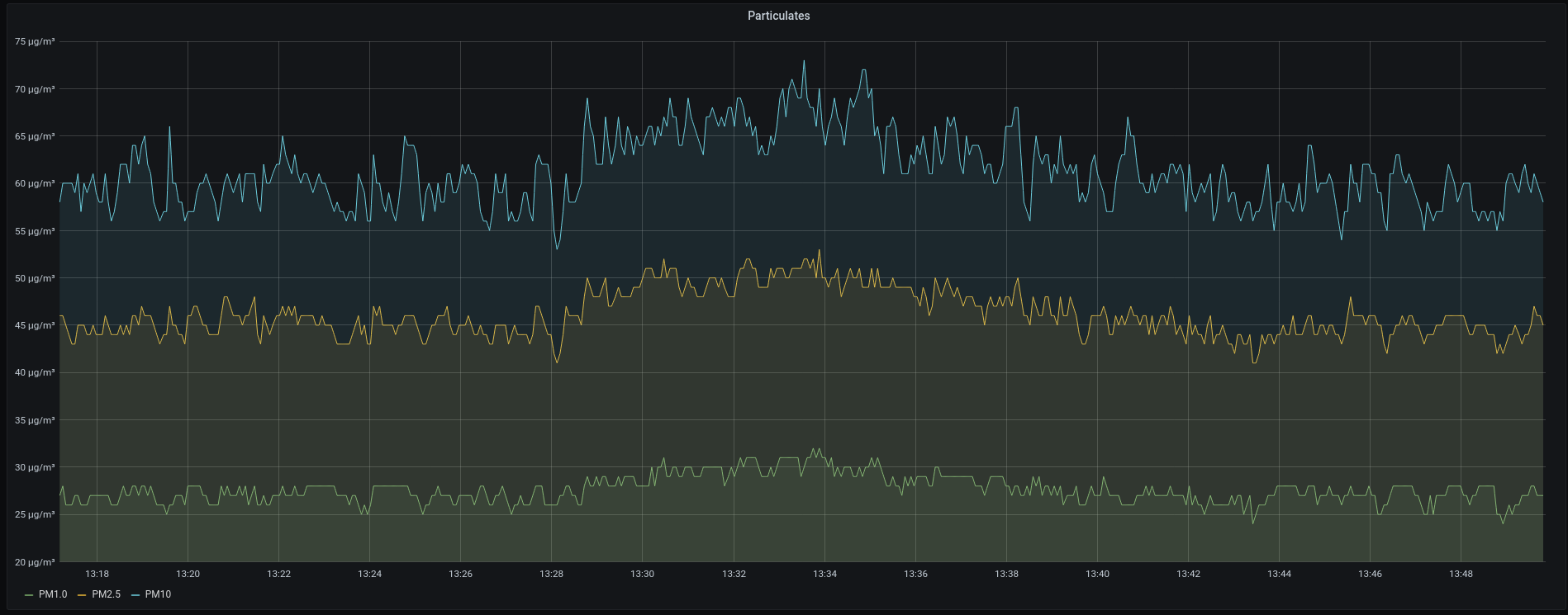\n\nI noticed that the air quality in my bedroom was not great.\nThe basement door is right outside my bedroom door, and is pretty leaky, so I started keeping my bedroom door closed.\nI also taped over my old, leaky windows with masking tape:\n\n\n\nThese interventions had a real effect!\n\n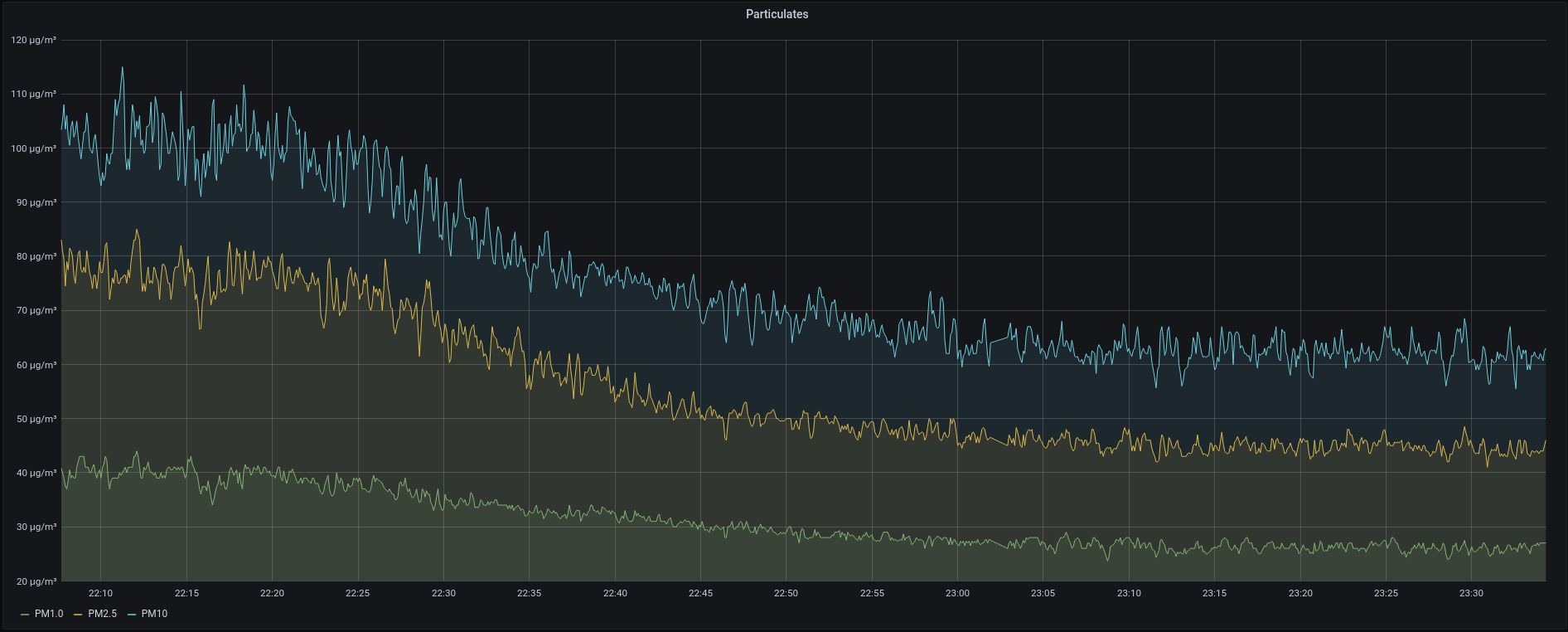\n\nFinally, it *is* possible to have *good* air quality.\nI'm currently sitting in my taped-up room, with doors closed, right next to a box-fan-with-filter:\n\n\n\nThe results, with other rooms in the house and outside the house on my Grafana dashboard:\n\n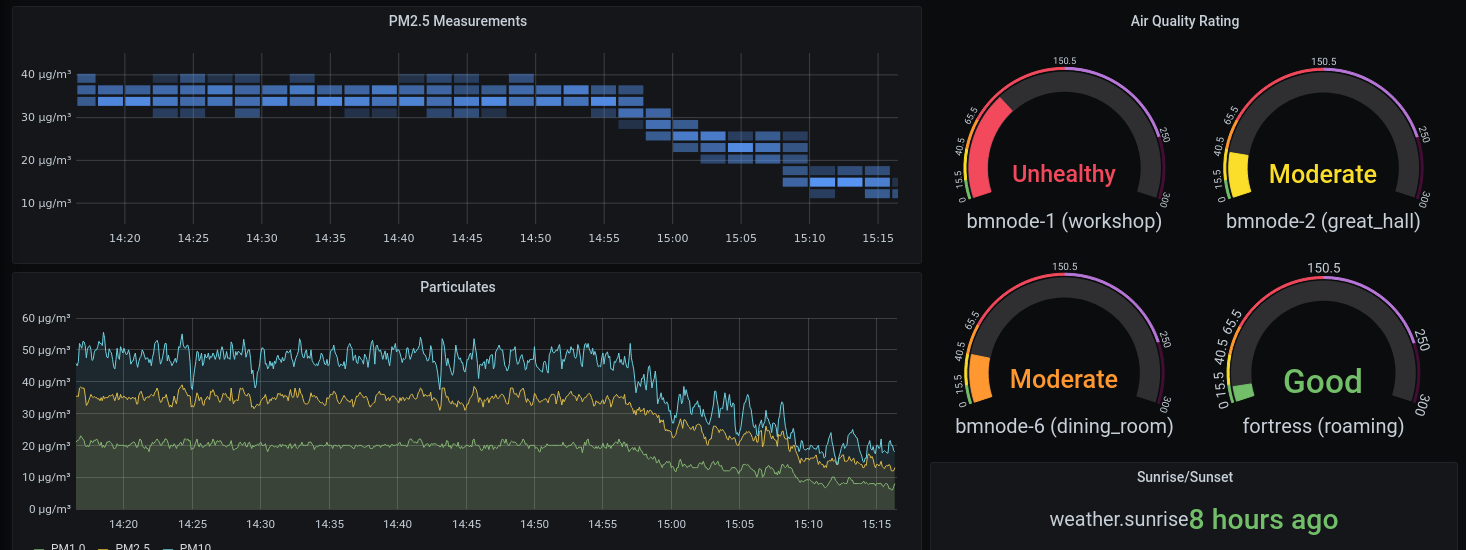\n\nSetting up `telegraf`, `influxdb`, and `grafana` is beyond the scope of this post.\nIf you do go this route, however, the `mini-aqm` code is already writing a log of collected data into a `measurements.log` file.\nYou can run the collector while you're working on the visualization setup, and then import the \"historical\" data you've collected when you're done.\n\n## What's Next?\n\nI'd like to help you breathe better air.\nReach out if you need help building these devices, or have any questions at all.\nAlso, if you're in the Bay Area, I have a few spare PMS7003 devices.\nIf you'd like one without waiting for them to be shipped from China, please reach out, and I can leave one on my porch for you to come grab.\n", "url": "https://igor.moomers.org/posts/minimal-viable-air-quality", "title": "Minimum Viable Air Quality Monitoring", "date_modified": "2020-09-13T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/building-etl-kubernetes", "content_html": "\nFrom December 2018 until May of 2020, I worked as a software engineer at [Aclima](https://aclima.io/).\nWhile I was there, I ended up building an in-house [ETL](https://en.wikipedia.org/wiki/Extract,_transform,_load) system written entirely in Python on Kubernetes.\nThough fairly generic, this system is, and likely will remain closed-source.\nHowever, I still learned a lot -- about ETL, Kubernetes, data science workflows -- and this post is an attempt to summarize those learnings.\n\nI would love to reflect generally on my time at Aclima, similar to my [reflections on leaving Airbnb](/thoughts-on-leaving-airbnb).\nI found it difficult to approach this as a single post, so I'm going to do it in pieces, of which this is one.\nStay tuned for more posts about other things I learned in the last 18 months.\n\n## What's Aclima ##\n\nWhen I joined, Aclima had just completed it's Series A, and was focused on building and scaling a new product.\nThe products customers were regulators, such as Bay Area's own [BAAQM](https://www.baaqmd.gov/) (or \"the district\").\nThese folks are in charge of making the air that citizens in their districts breathe as clean as possible.\nTo do this, they need *data* -- how good is the air, what are some problem areas or pollutants, what is the effect of various interventions.\n\nTraditionally, that data has primarily come from permanent EPA monitoring sites.\nThese contain very expensive regulatory- or lab-grade equipment that has been strenuously vetted to give accurate readings.\nThis equipment has to be secured and property maintained to retain accuracy.\nAs a result, there are not that many such regulatory sites -- here's a map of the Bay Area ones from the [airnow.gov](https://fire.airnow.gov/?lat=37.86988000000008&lng=-122.27053999999998&zoom=12#) website:\n\n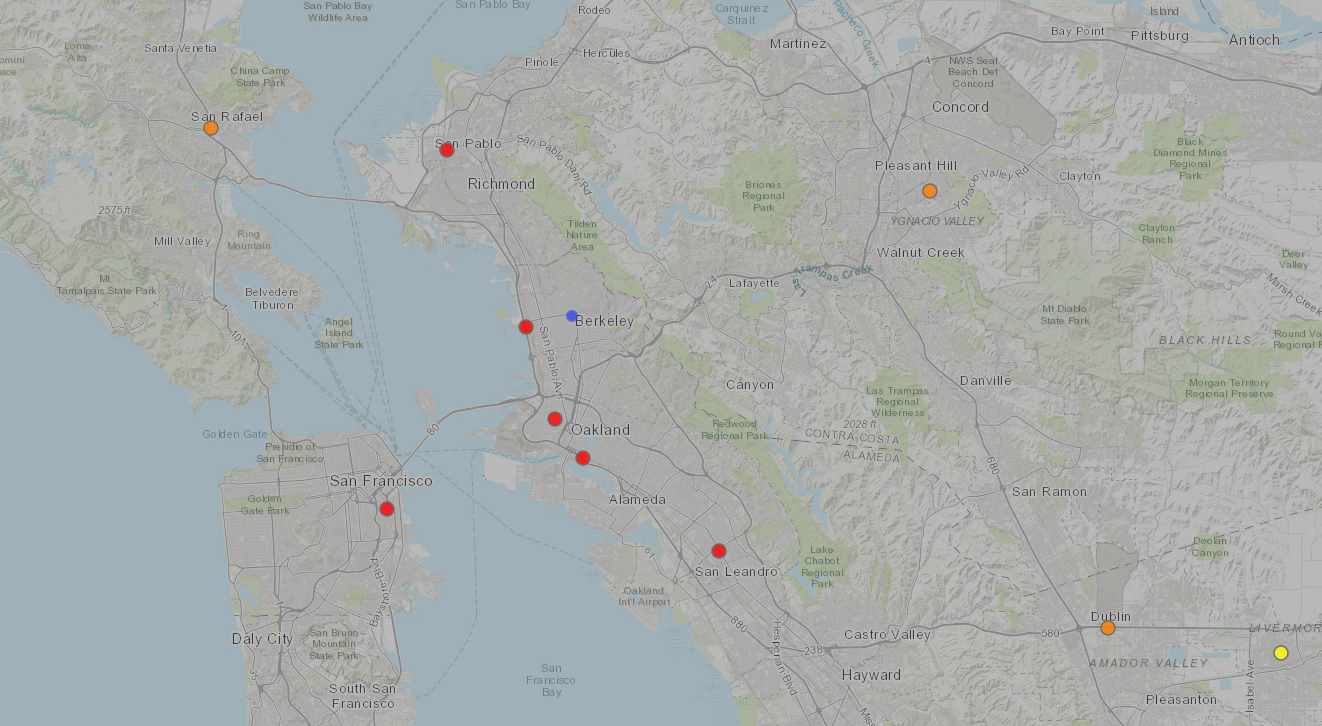\n\nThe problem is that, while the reference stations give very accurate data, that data is only very accurate for the small area immediately adjacent to the regulatory site.\nAir quality, on the other hand, can differ dramatically, even block-by-block.\nIt's strongly affected by the presence of [major roadways](https://www.epa.gov/air-research/research-near-roadway-and-other-near-source-air-pollution), [toll booths](https://www.macfound.org/media/files/HHM_Research_Brief_-_Living_Along_a_Busy_Highway.pdf), [restaurants](https://www.theguardian.com/environment/2019/oct/10/restaurants-contribution-to-air-pollution-revealed), features of the landscape, and many other factors.\n\nAclima's goal was to quantify this local variability by collecting \"hyperlocal\" air quality measurements.\nEven with the advent of [low-cost sensors](https://www.alibaba.com/product-detail/PLANTOWER-Laser-PM2-5-DUST-SENSOR_62480702957.html) and [cheap connected devices](https://en.wikipedia.org/wiki/ESP32), installing and maintaining thousands of devices on every street would be a challenge.\nInstead, Aclima builds out vehicles equipped with a suite of sensors, and then drives those vehicles down every block -- many times, to collect a representative number of samples.\n\n## Overall Architecture ##\n\nWhat are the technical details around implementing such a data collection system?\nThere are lots of moving -- sometimes, literally moving -- pieces here.\nFirst, a bunch of hardware must be spec'ed, sourced, integrated, and tested.\nThe hardware needs software which can collect data from a suite of sensors, and then the software needs to report this data back to a centralized backend.\nThe data must be collected, stored, and processed.\nFinally, there's a presentation or product layer, which allows customers to gain insights from the pile of data points.\n\nOver my time at Aclima, I worked on all of these components.\nFor instance, I built a tool which generated [STM32](https://www.st.com/en/microcontrollers-microprocessors/stm32-32-bit-arm-cortex-mcus.html) firmware and then flashed it onto boards using [dfu-util](http://dfu-util.sourceforge.net/).\nI experimented with rapidly prototyping low-cost hardware (post coming soon).\nI also worked on fleet-level IOT device management and data collection.\n\nHowever, most of my time at Aclima was spent on the pipeline for processing the data that our vehicles and sensors collected.\nI'd like to focus this post on the technical details behind this component.\n\n## Why Kubernetes? ##\n\nMy immediate project was taking some code written by a data scientist, which had only ever been running on her laptop, and making it run regularly and on some other system.\nThis involved configuring an environment for this code -- the correct versions of python, libraries, and system dependencies.\nI would need to keep the environment in-sync between the OSX laptops of other engineers and data scientists, and the cloud environment where the code ran in production.\nI wanted the ability to have representative local tests, but also a rapid-iteration development environment.\nFinally, I didn't want to introduce too many workflow changes -- only the barest minimum necessary.\n\nThe choice of tooling was already somewhat constrained.\nAclima was already running in the [Google Cloud](http://dfu-util.sourceforge.net/), and many of their existing services ran in pods on Google's [Kubernetes Engine](https://cloud.google.com/kubernetes-engine/).\nMost of my experience was with raw EC2 instances configured with [chef](https://medium.com/airbnb-engineering/making-breakfast-chef-at-airbnb-8e74efff4707), and I was unfamiliar with the Docker ecosystem.\nHowever, I was also unfamiliar with Cloud ETL tools like [Dataflow](https://cloud.google.com/dataflow/) and was reluctant to jump into a ecosystem new for both myself and my colleagues.\nThe other obvious choice would have been [Airflow](https://airflow.apache.org/); Google even has a [hosted version](https://cloud.google.com/composer/).\nHowever, at the time (early 2019), Airflow did not have good support for Kubernetes, and I would have had to configure instances for code to execute on.\n\nIn any case, my first task was fairly simple -- take a Python program which is already running locally, and make it run in the cloud.\nI wrote a Dockerfile to correctly configure the environment, copied the code into the docker image, and uploaded it to [GCR](https://cloud.google.com/container-registry/).\nI used the [Kubernetes CronJob controller](https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/) to get it to run daily, and [K8s secrets](https://kubernetes.io/docs/concepts/configuration/secret/) to manage credentials for the process.\nBy configuring the [cluster autoscaler](https://cloud.google.com/kubernetes-engine/docs/concepts/cluster-autoscaler), we could avoid paying for cluster resources when we didn't need them.\nWhenever the job ran, if the cluster didn't have enough resources, GKE would automatically add them, and then clean up after the job completed.\n\nThe local setup for users involved installing docker and the [gcloud](https://cloud.google.com/sdk/gcloud/) tool, and getting `gcloud` authenticated.\n`gcloud` takes care of managing permissions for the K8s cluster/the [`kubectl` command](https://kubernetes.io/docs/reference/kubectl/overview/), which is invoked to deploy the `CronJob` and `Secret` manifests.\nTo shield users (and myself!) from the raw `docker` and `kubectl` commands, I immediately added [`invoke`](https://www.pyinvoke.org/) to the data science repo.\nAfter getting the ETL job running locally, the workflow to deploy it to production was a simple `inv build` and `inv deploy`.\nI also created convenience tooling, like `inv jobs.schedule`, to do a one-time run of the job in the cloud, and `inv jobs.follow` to tail it's output.\n\nThese initial steps were simple and easy enough that we decided to continue with Kubernetes for a while, and reconsider when we hit snags.\n\n## Scaling Up to Multiple Jobs ##\n\nOne job does not an ETL pipeline make.\nA few changes were required to add a second job to the pipeline.\nFirst, we wrote the second job in the same repo as the first.\nWe standardized on a job format -- a Python class with a signature like so:\n\n```python\nclass PerformType(Protocol):\n def __call__(\n self, start: pendulum.DateTime, end: pendulum.DateTime, config: Dict[str, Any]\n ) -> None:\n pass\n\nclass JobType(Protocol):\n perform: PerformType\n```\n\nWe then created a standard `main.py` entrypoint which would accept parameters like the job name and options, and dispatch them to the correct job class.\n\nThe Kubernetes work is a little more complicated.\nThe jobs look basically the same, but have different arguments -- in K8s-speak, the pod spec container args -- are different.\nThe solution is to template the K8s manifests, but templating a data structure (in this case, `yaml`) like a string (e.g., with [jinja](https://jinja.palletsprojects.com/en/2.11.x/)) is a recipe for disaster, and popular tools like [jsonnet](https://jsonnet.org/) seem quite heavyweight.\n\nWe managed to find [json-e](https://json-e.js.org/), which hit just the right note.\nThis allows you to template and render a pod manifest:\n\n```yaml\nspec:\n containers:\n - name: {$eval: 'container_name'}\n image: {$eval: 'image'}\n args: {$eval: 'args'}\n```\n\nwith something like:\n\n```python\npod_manifest = jsone.render(\n YAML(typ=\"safe\").load('pod_manifest.yaml'),\n {\n 'container_name': job_name,\n 'image': 'latest',\n 'args': [job_name, start_time, end_time, job_config]\n }\n)\n```\n\nYou end up with a valid pod manifest as a data structure.\nYou can then render it into your `CronJob` manifest:\n\n```yaml\napiVersion: batch/v1beta1\nkind: CronJob\nspec:\n schedule: {$eval: schedule}\n jobTemplate:\n spec:\n template: {$eval: pod_manifest}\n```\n\nin the same way:\n\n```python\ncron_manifest = jsone.render(\n YAML(typ=\"safe\").load('cron_manifest.yaml'),\n {\n 'schedule': '0 2 * * *',\n 'pod_manifest': pod_manifest,\n }\n)\n```\n\nThe resulting `cron_manifest` can be serialized to YAML again, and passed to `kubectl apply` to update your resources:\n\n```python\nwith NamedTemporaryFile() as ntf:\n ntf.write(YAML(typ=\"safe\").dump(cron_manifest))\n ntf.flush()\n \n os.system(f\"kubectl apply -f {ntf.name}\")\n```\n\nOf course, we updated our `inv` tooling to support gathering input from users about which jobs they wanted to deploy, and with which arguments.\nWe also provided helpers for the `main.py` dispatcher, so you could specify arguments like `yesterday` to a job and have it run over the previous day.\n\n## Inter-job Dependencies ##\n\nSoon enough, we had dozens of jobs, and they had inter-job dependencies.\nYou can only go so far by saying \"job A runs at 2 am, and usually finishes in an hour, so we'll run job B at 3:30 am\".\n\nThis was time, again, to re-examine existing popular open-source tooling, and we seriously considered [Argo](https://argoproj.github.io/argo/).\nBut again, some functionality was missing -- specifically, we got bit by [this bug](https://github.com/argoproj/argo/issues/703#issuecomment-494183536) preventing the templating of resources, which was a step back from being able to template any part of the manifest using `json-e`.\n\nInstead, we ended up creating two new concepts.\nThe first, a `workflow`, listed all the jobs that depended on each other, along with their dependency relationships, encoding a [DAG](https://en.wikipedia.org/wiki/Directed_acyclic_graph).\nIt's easy to parse a YAML list, and verify that it is indeed a DAG, with [networkx](https://networkx.github.io/documentation/stable/reference/algorithms/dag.html).\nCreating a workflow specification also gave us a place to keep track of standard job parameters, such as command-line options or resource requirements for a job.\n(As an aside, resource management for jobs was a constant chore, especially as the product was scaled up and data volumes increased.)\n\nThe second concept was a `dispatcher` job.\nInstead of actually doing ETL work, this type of job, when dispatched using a `CronJob` resource, would accept a workflow as an argument, and then dispatch all the jobs in that workflow definition.\nA job would not get dispatched until the jobs it depended on completed successfully.\nThis allowed us to schedule a workflow to run daily instead of scheduling a pile of jobs individually.\nMost of the code was re-cycled from the code already used by users locally to schedule their jobs -- the `dispatcher` was doing the same thing, just from *inside* Kubernetes.\n\n## Monitoring via Web UI ##\n\nAs the complexity of the ETL pipeline grew, we began encountering workflow failures.\nWe needed an audit log of which jobs ran for which days, so we could confirm that we were delivering the data we processed.\nWe also needed tooling to reliably re-process certain days of data, and keep track of those re-processing runs.\n\nBy this point, the ETL system we were building had run for a year without requiring any UI beyond the one provided by GKE and `kubectl`.\nHowever, to manage the complexity, it seemed like a UI was needed.\nI ended up building one using [firestore](https://cloud.google.com/firestore/), React, and [ag-grid](https://www.ag-grid.com/).\n\nPreviously, the `dispatcher` job that ran workflows was end-to-end responsible for all the jobs in the workflow.\nIt ran for as long as any job in the workflow was running.\nIf any of the jobs failed the `dispatcher` would exit, and the subsequent jobs would not run.\nLikewise, if `dispatcher` itself failed, remaining workflow jobs would be left orphaned.\n\nInstead, we turned the workflow `dispatcher` into something that merely manipulated the state in `firestore`.\nThe job would parse the workflow `.yaml` file into a DAG, and then create `firestore` entries for each job in the graph.\nThe `firestore` entry would include job parameters like command-line arguments and resource requests, as well as job dependency information.\nJobs at the head of the DAG would be placed into a `SCHEDULED` state, while jobs that were dependent on other jobs were placed into a `BLOCKED` state.\n\nAn always-running K8s service called `scheduler` would subscribe to `firestore` updates and take action when jobs were created or changed state.\nFor instance, if a job was in the `SCHEDULED` status, the `scheduler` would create pods for those jobs via the K8s API, and then mark them as `RUNNING`.\nIf a task finished (by marking itself as `COMPLETED`), the `scheduler` would notice, and clean up the completed pods.\nIt would also check if any jobs were `BLOCKED` waiting on the completed job, make sure all their dependencies had completed, and placed them into the `SCHEDULED` state.\nIf a job marked itself as `FAILED` (via a catch-all exception handler), we had the option to track retries and re-schedule the job.\n\nBecause the `scheduler` became the only thing that interacted with the K8s API, it made building user-facing tooling easier.\nThose tools merely had to manipulate the DB state in `firestore`.\nThis enabled less technical users, without `gcloud` or `kubectl` permissions, to create, terminate, restart, and monitor job and workflow progress.\n\nFrom what I can tell, components like the `scheduler` are often built using K8s [operators](https://kubernetes.io/docs/concepts/extend-kubernetes/operator/) and [custom resources](https://kubernetes.io/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions/).\nHowever, we found that just running a service with permissions to manage pods is sufficient.\nThis avoids having to dive too deep into K8s internals, beyond the basic API calls necessary to create and remove pods and check on their status.\n\n## Parallelism ##\n\nSome jobs in our system were trivially parallelise-able, e.g. because they processed a single sensor's data in isolation.\nThe system of using the `scheduler` to run additional jobs unlocked infinite parallelism inside jobs.\nFor instance, we could schedule a job like `ProcessAllSensors`.\nThis job would first list all sensors active during the `start`/`end` interval, and then could create a child job in `firestore` for each sensor.\nCreating child jobs was as simple as writing a job entry into `firestore`, with the ID of the sensor to process.\nParallelism was limited only by the auto-scaling constraints on the K8s cluster.\n\nI created an abstraction called `TaskPoolExecutor`, based on the existing [`ThreadPoolExecutor`](https://docs.python.org/3/library/concurrent.futures.html#threadpoolexecutor).\nEach job submitted to the `executor` would run in a different K8s pod.\nNot only did this make data processing much faster, but more resilient, too.\nPreviously, if a particular sensor failed in it's processing, restarting that processing was complicated.\nIn the new system, the existing retry system baked into the `scheduler` could retry individual sensors, without the parent job even knowing about it.\n\n## Takeaway ##\n\nMy focus at Aclima was on business objectives -- making sure data is delivered, data scientists and other technicians are productive, and we can manage our fleets of vehicles and devices.\nIn 18 months, I was able to build an infinitely-auto-scalable, reliable parallel job scheduling system and UI accessible to non-technical users.\nI was able to build this one step at a time, from \"how do I regularly run one cron job\" all the way to \"how to I parallelize and monitor a run of a job graph over a year of high-precision sensor data\".\n\nI think this is a tribute to the power of the abstractions that Kubernetes provides.\nIt's an infinite pile of compute, and it's pretty easy to utilize it.\nThis experience has sold me on the premise, and I would definitely use Kubernetes for other projects again.\n\n## Do Differentlys ##\n\nThe scheduler and all the code that interacts with K8s was written in Python, mostly because the data processing code was also written in Python.\nHowever, as soon as I wanted to add a UI, I had to begin writing Javascript.\nThis means I have to share at least data structures -- for instance, the structure of a `job` in firestore -- between the two languages.\nIn the future, if I'm writing a UI, even a CLI, I will consider strongly whether I should just write it in JS to begin with.\n", "url": "https://igor.moomers.org/posts/building-etl-kubernetes", "title": "Kubernetes for ETL", "date_modified": "2020-09-10T00:00:00.000Z" }, { "id": "https://igor.moomers.org/posts/aws-mfa-cli-direnv", "content_html": "\nYou might already be using multi-factor authentication (MFA) for logins to your AWS account.\nThis will cause AWS to prompt you for your MFA token when you log in via the web console.\nHowever, if you use AWS via command-line tools (e.g., `terraform` or `aws s3`), you might have issued yourself access keys.\nThose are single-factor, and if they leak, anyone on the internet can use them to do horrible things to your account.\n\nWe can make your admin AWS accounts safer by requiring MFA, even for API requests.\nFirst, put your account, and the account of all other admins in your AWS account, in a group like `AdminMFA`.\nThis group should have a policy that looks like this:\n\n```json\n{\n \"Version\": \"2012-10-17\",\n \"Statement\": [\n {\n \"Effect\": \"Allow\",\n \"Action\": [\n \"*\"\n ],\n \"Resource\": \"*\",\n \"Condition\": {\n \"Bool\": {\n \"aws:MultiFactorAuthPresent\": \"true\"\n }\n }\n }\n ]\n}\n```\n\n## Direnv Config ##\n\nNow, you'll need a mechanism to authenticate via your MFA token, get a session token, and put that session token into your environment.\nI do this using [`direnv`](https://direnv.net/).\nI've only recently learned about `direnv`, and I'm already using it, in combination with [`asdf`](https://asdf-vm.com/#/core-manage-asdf-vm), to replace [`rbenv`](https://github.com/rbenv/rbenv), [`pyenv`](https://github.com/pyenv/pyenv), and [`nodenv`](https://github.com/nodenv/nodenv).\n`direnv` and `asdf` setup is beyond the scope of this post, but you can check out [my dotfiles repo](https://github.com/igor47/dotfiles) to get an idea of how I have it configured.\n\nHere's my configuration in a `.envrc` file of a [terraform](https://www.terraform.io/) repo for a project hosted on AWS:\n\n```bash\nuse asdf\n\nexport MASTER_AWS_ACCESS_KEY_ID=AKIA